Toàn Tập Kubernetes: Từ Zero đến Hero cho Developer
Mục Lục
Phần I: Nhập Môn Kubernetes - Nền Tảng Vững Chắc
Chương 1: Tại Sao Lại Là Kubernetes? Lịch Sử và Bối Cảnh
- 1.1. Kỷ nguyên trước Container: Máy ảo và những nỗi đau.
- 1.2. Docker và cuộc cách mạng Containerization.
- 1.3. Sự ra đời của Kubernetes: Kế thừa từ Google Borg.
- 1.4. Kubernetes giải quyết bài toán gì? (Container Orchestration).
- 1.5. So sánh Kubernetes với các đối thủ: Docker Swarm, Mesos.
- 1.6. Hệ sinh thái Kubernetes: CNCF và các dự án liên quan.
Chương 2: Kiến Trúc Tổng Quan của Kubernetes
- 2.1. Mô hình Master-Node (Control Plane & Data Plane).
- 2.2. Các thành phần của Control Plane:
- 2.2.1.
kube-apiserver: Cửa ngõ của mọi tương tác. - 2.2.2.
etcd: Bộ não và trái tim của cluster. - 2.2.3.
kube-scheduler: Người điều phối tài nguyên thông thái. - 2.2.4.
kube-controller-manager: Cỗ máy duy trì trạng thái. - 2.2.5.
cloud-controller-manager: Tích hợp với nhà cung cấp đám mây.
- 2.2.1.
- 2.3. Các thành phần của Worker Node:
- 2.3.1.
kubelet: "Đại sứ" của Control Plane tại mỗi Node. - 2.3.2.
kube-proxy: Nhạc trưởng của mạng lưới. - 2.3.3.
Container Runtime: Động cơ thực thi (Docker, containerd, CRI-O).
- 2.3.1.
- 2.4. Luồng hoạt động của một yêu cầu: Từ
kubectlđến khi Pod được tạo.
Chương 3: Cài Đặt Môi Trường và Công Cụ Thiết Yếu
- 3.1.
kubectl: Giao tiếp với Kubernetes Cluster.- 3.1.1. Cài đặt và cấu hình
kubectl. - 3.1.2. Các lệnh
kubectlcơ bản và cần thiết nhất. - 3.1.3. Mẹo và thủ thuật với
kubectl(alias, plugins, output formatting).
- 3.1.1. Cài đặt và cấu hình
- 3.2. Xây dựng một Kubernetes Cluster cục bộ cho Developer:
- 3.2.1. Minikube: Nhanh, gọn, nhẹ.
- 3.2.2. Kind (Kubernetes in Docker): Cluster đa node trong Docker.
- 3.2.3. Docker Desktop Kubernetes: Tích hợp sẵn tiện lợi.
- 3.2.4. So sánh và lựa chọn công cụ phù hợp.
- 3.3. Các công cụ hỗ trợ khác:
- 3.3.1.
k9s: Giao diện terminal mạnh mẽ để quản lý cluster. - 3.3.2.
Lens: "IDE cho Kubernetes".
- 3.3.1.
- 3.1.
Phần II: Các Khái Niệm Cốt Lõi trong Kubernetes
Chương 4: Pod - Đơn Vị Nhỏ Nhất
- 4.1. Pod là gì? Tại sao không phải là Container?
- 4.2. Vòng đời của Pod (Pod Lifecycle).
- 4.3. Cấu hình một Pod: File YAML đầu tiên của bạn.
- 4.4. Pod đa container (Multi-container Pods) và các mẫu thiết kế (Sidecar, Ambassador, Adapter).
- 4.5. Init Containers: Khởi tạo trước khi container chính chạy.
- 4.6. Static Pods: Pod được quản lý trực tiếp bởi
kubelet.
Chương 5: Controllers - Quản Lý Vòng Đời Ứng Dụng
- 5.1.
ReplicaSet: Đảm bảo số lượng Pod luôn ổn định. - 5.2.
Deployment: Trái tim của ứng dụng stateless.- 5.2.1. Khai báo một Deployment.
- 5.2.2. Chiến lược cập nhật (Rolling Update, Recreate).
- 5.2.3. Rollback về phiên bản trước.
- 5.2.4.
RevisionHistoryLimit.
- 5.3.
StatefulSet: Dành cho ứng dụng có trạng thái.- 5.3.1. Sự khác biệt với Deployment.
- 5.3.2. Định danh mạng ổn định (Stable Network ID).
- 5.3.3. Lưu trữ ổn định (Stable Storage).
- 5.3.4. Cập nhật và scaling có thứ tự.
- 5.4.
DaemonSet: Chạy một Pod trên mỗi Node. - 5.5.
JobvàCronJob: Tác vụ chạy một lần và theo lịch trình.
- 5.1.
Chương 6: Service & Ingress - Kết Nối Với Thế Giới Bên Ngoài
- 6.1. Vấn đề kết nối trong Kubernetes.
- 6.2.
Service: Trừu tượng hóa kết nối đến Pods.- 6.2.1.
ClusterIP: Service nội bộ. - 6.2.2.
NodePort: Mở port trên mỗi Node. - 6.2.3.
LoadBalancer: Tích hợp với Load Balancer của cloud. - 6.2.4.
ExternalName: Alias cho service bên ngoài.
- 6.2.1.
- 6.3. Service Discovery: Kubernetes DNS.
- 6.4.
Ingress: Quản lý truy cập HTTP/HTTPS từ bên ngoài.- 6.4.1. Ingress Controller là gì? (Nginx, Traefik, HAProxy).
- 6.4.2. Cấu hình Ingress cho routing dựa trên host và path.
- 6.4.3. Cấu hình TLS/SSL.
- 6.5.
Gateway API: Tương lai của Ingress.
Chương 7: ConfigMap & Secret - Quản Lý Cấu Hình
- 7.1. Tách biệt cấu hình khỏi code.
- 7.2.
ConfigMap: Lưu trữ dữ liệu cấu hình không nhạy cảm.- 7.2.1. Tạo ConfigMap từ file, thư mục, literal.
- 7.2.2. Sử dụng ConfigMap trong Pod (Environment variables, Volume).
- 7.3.
Secret: Quản lý dữ liệu nhạy cảm.- 7.3.1. Các loại Secret.
- 7.3.2. Mã hóa Base64 và những lầm tưởng về bảo mật.
- 7.3.3. Sử dụng Secret trong Pod.
- 7.3.4. Các giải pháp quản lý Secret nâng cao (Vault, Sealed Secrets).
Chương 8: Storage - Lưu Trữ Dữ Liệu Bền Bỉ
- 8.1. Vấn đề lưu trữ trong môi trường container.
- 8.2.
Volume: Vòng đời và các loại Volume. - 8.3.
PersistentVolume(PV) vàPersistentVolumeClaim(PVC): Trừu tượng hóa lưu trữ. - 8.4.
StorageClass: Cấp phát Volume động (Dynamic Provisioning). - 8.5.
Access Modes: ReadWriteOnce, ReadOnlyMany, ReadWriteMany. - 8.6. Các giải pháp lưu trữ cho Kubernetes (NFS, Ceph, GlusterFS, Cloud Storage).
Phần III: Vận Hành và Tối Ưu Hóa cho Developer
Chương 9: Health Checks và Quản Lý Tài Nguyên
- 9.1.
Liveness Probe: Pod của bạn có còn "sống"? - 9.2.
Readiness Probe: Pod đã sẵn sàng nhận request chưa? - 9.3.
Startup Probe: Dành cho các ứng dụng khởi động chậm. - 9.4.
RequestsvàLimits: Quản lý CPU và Memory. - 9.5.
Quality of Service(QoS) Classes: Guaranteed, Burstable, BestEffort. - 9.6.
ResourceQuotavàLimitRange: Giới hạn tài nguyên ở mức Namespace.
- 9.1.
Chương 10: Logging, Monitoring và Debugging
- 10.1. Logging:
- 10.1.1. Ghi log ra
stdoutvàstderr. - 10.1.2. Kiến trúc logging trong Kubernetes (Node-level, Cluster-level).
- 10.1.3. Bộ công cụ EFK/Loki-Promtail.
- 10.1.1. Ghi log ra
- 10.2. Monitoring:
- 10.2.1. Các chỉ số quan trọng cần theo dõi.
- 10.2.2.
Metrics Server. - 10.2.3.
PrometheusvàGrafana: Tiêu chuẩn vàng của monitoring.
- 10.3. Debugging:
- 10.3.1.
kubectl logs,kubectl describe,kubectl exec. - 10.3.2. Debugging Pods bị lỗi (CrashLoopBackOff, ImagePullBackOff).
- 10.3.3.
Ephemeral Containersđể debug live. - 10.3.4. Port-forwarding để truy cập ứng dụng.
- 10.3.1.
- 10.1. Logging:
Chương 11: Tối Ưu Hóa Quy Trình Phát Triển (Development Workflow)
- 11.1. Vòng lặp phát triển: Code -> Build -> Deploy -> Test.
- 11.2.
Skaffold: Tự động hóa vòng lặp phát triển trên Kubernetes. - 11.3.
Telepresence: Phát triển và debug service cục bộ như thể nó đang chạy trong cluster. - 11.4.
DevSpace: Một lựa chọn mạnh mẽ khác. - 11.5. Xây dựng Docker image hiệu quả cho Kubernetes.
Phần IV: Helm - Trình Quản Lý Gói cho Kubernetes
Chương 12: Giới Thiệu về Helm
- 12.1. Helm là gì và tại sao nó cần thiết?
- 12.2. Các khái niệm cốt lõi: Chart, Release, Repository.
- 12.3. Kiến trúc Helm (Helm 3).
- 12.4. Cài đặt và cấu hình Helm.
Chương 13: Sử Dụng Helm Chart
- 13.1. Tìm kiếm Chart từ các repository (Artifact Hub).
- 13.2. Cài đặt một Chart (
helm install). - 13.3. Tùy chỉnh Chart với file
values.yaml. - 13.4. Quản lý các Release (
helm list,helm status,helm upgrade,helm rollback,helm uninstall).
Chương 14: Xây Dựng Helm Chart của Riêng Bạn
- 14.1. Cấu trúc của một Chart (
Chart.yaml,values.yaml,templates/,charts/). - 14.2. Go Templating Engine: Ngôn ngữ của Helm.
- 14.2.1. Biến, hàm, và pipelines.
- 14.2.2. Các đối tượng tích hợp sẵn (
.Values,.Release,.Chart). - 14.2.3. Luồng điều khiển (if/else, range).
- 14.2.4. Named Templates (
_helpers.tpl).
- 14.3. Quản lý các Chart phụ thuộc (Dependencies).
- 14.4.
helm lintvàhelm template: Debugging Chart của bạn. - 15.5. Đóng gói và chia sẻ Chart (
helm package, Chart Repository).
- 14.1. Cấu trúc của một Chart (
Phần V: Các Chủ Đề Nâng Cao và Mở Rộng
Chương 15: Bảo Mật trong Kubernetes cho Developer
- 15.1.
RBAC(Role-Based Access Control): Ai được làm gì?- 15.1.1.
Role,ClusterRole,RoleBinding,ClusterRoleBinding.
- 15.1.1.
- 15.2.
ServiceAccount: Định danh cho ứng dụng. - 15.3.
PodSecurityPolicy/Pod Security Admission. - 15.4.
NetworkPolicy: Tường lửa cho Pods. - 15.5. Quét lỗ hổng bảo mật trong container image.
- 15.1.
Chương 16: CI/CD với Kubernetes
- 16.1. Tổng quan về CI/CD trong thế giới Kubernetes.
- 16.2. Tích hợp Kubernetes với Jenkins.
- 16.3. Tích hợp Kubernetes với GitLab CI/CD.
- 16.4.
Argo CD: GitOps - "Infrastructure as Code" cho Kubernetes. - 16.5.
Flux CD: Một lựa chọn GitOps phổ biến khác.
Chương 17: Service Mesh - Quản Lý Giao Tiếp Giữa Các Service
- 17.1. Service Mesh là gì?
- 17.2.
Istio: Giới thiệu và kiến trúc. - 17.3.
Linkerd: Đơn giản và hiệu quả. - 17.4. Các tính năng chính: Traffic Management, Observability, Security.
Chương 18: Mở Rộng Kubernetes với Operators và CRDs
- 18.1.
Custom Resource Definitions(CRDs): Mở rộng Kubernetes API. - 18.2.
Operator Pattern: Tự động hóa quản lý ứng dụng phức tạp. - 18.3. Xây dựng một Operator đơn giản với
Operator SDKhoặcKubebuilder.
- 18.1.
Phụ Lục
- A: Bảng thuật ngữ Kubernetes.
- B: Tổng hợp các lệnh
kubectlhữu ích. - C: Các lỗi thường gặp và cách khắc phục.
- D: Tài liệu tham khảo và các khóa học đề xuất.
Phần I: Nhập Môn Kubernetes - Nền Tảng Vững Chắc
Chương 1: Tại Sao Lại Là Kubernetes? Lịch Sử và Bối Cảnh
Để thực sự hiểu được sức mạnh và sự cần thiết của Kubernetes, chúng ta cần quay ngược thời gian, nhìn lại hành trình phát triển của việc triển khai ứng dụng. Đó là một câu chuyện về sự tiến hóa, từ những cỗ máy vật lý cồng kềnh đến một thế giới linh hoạt, tự động và có khả năng co giãn gần như vô hạn.
1.1. Kỷ nguyên trước Container: Máy ảo và những nỗi đau
Trước khi container trở thành một thuật ngữ phổ biến, thế giới hạ tầng phần mềm được thống trị bởi Máy chủ vật lý (Bare Metal) và sau đó là Máy ảo (Virtual Machines - VMs).
Thời kỳ Máy chủ vật lý: Mỗi ứng dụng được cài đặt trực tiếp lên một máy chủ vật lý riêng biệt. Cách tiếp cận này có những nhược điểm chí mạng:
- Lãng phí tài nguyên: Một ứng dụng hiếm khi sử dụng hết 100% công suất của một máy chủ hiện đại. Phần lớn CPU, RAM và dung lượng lưu trữ bị bỏ không, gây ra sự lãng phí chi phí khổng lồ.
- Chi phí vận hành cao: Việc bảo trì, nâng cấp, và quản lý hàng trăm, hàng nghìn máy chủ vật lý đòi hỏi một đội ngũ vận hành lớn và chi phí điện năng, không gian đáng kể.
- Thiếu linh hoạt: Việc triển khai một ứng dụng mới đồng nghĩa với việc phải mua sắm, cài đặt và cấu hình một máy chủ mới, một quy trình có thể mất hàng tuần hoặc hàng tháng.
Sự ra đời của Máy ảo (VMs): Công nghệ ảo hóa xuất hiện như một vị cứu tinh. Một Hypervisor (như VMware ESXi, KVM, Hyper-V) được cài đặt trên máy chủ vật lý, cho phép tạo ra nhiều máy ảo độc lập trên cùng một phần cứng. Mỗi VM có hệ điều hành, thư viện và ứng dụng riêng.
VMs đã giải quyết được nhiều vấn đề:
- Tối ưu hóa tài nguyên: Nhiều VM có thể chạy trên cùng một máy chủ vật lý, tận dụng tối đa phần cứng.
- Tăng tính linh hoạt: Việc tạo ra một VM mới nhanh hơn nhiều so với việc chuẩn bị một máy chủ vật lý.
- Cô lập tốt hơn: Các VM được cách ly hoàn toàn với nhau. Một lỗi trong VM này không ảnh hưởng đến các VM khác.
Tuy nhiên, VMs cũng mang trong mình những "nỗi đau" mới:
- Cồng kềnh: Mỗi VM chứa một hệ điều hành đầy đủ, chiếm dụng hàng GB dung lượng và tiêu tốn một lượng RAM và CPU đáng kể chỉ để duy trì chính nó.
- Khởi động chậm: Việc khởi động một VM cũng chính là khởi động một hệ điều hành, quá trình này có thể mất vài phút.
- "Địa ngục" phụ thuộc (Dependency Hell): Mặc dù ứng dụng được đóng gói trong VM, nhưng việc quản lý các phiên bản thư viện, dependencies giữa các môi trường (development, testing, production) vẫn là một thách thức.
1.2. Docker và cuộc cách mạng Containerization
Năm 2013, Docker xuất hiện và thay đổi cuộc chơi mãi mãi. Docker giới thiệu một khái niệm không mới nhưng được đóng gói lại một cách cực kỳ thân thiện và mạnh mẽ: Container.
Container là gì? Hãy tưởng tượng container như một phiên bản cực kỳ nhẹ của VM. Thay vì ảo hóa toàn bộ phần cứng, container chỉ ảo hóa ở cấp độ hệ điều hành. Tất cả các container trên cùng một máy chủ sẽ chia sẻ chung nhân (kernel) của hệ điều hành máy chủ.
Mỗi container chỉ chứa ứng dụng và các thư viện/dependencies cần thiết của nó. Điều này mang lại những lợi ích vượt trội:
- Siêu nhẹ: Container chỉ nặng vài chục MB, so với hàng GB của VM.
- Khởi động tức thì: Khởi động một container chỉ mất vài giây hoặc thậm chí mili giây.
- Tính di động (Portability): "Build once, run anywhere". Một container được xây dựng trên máy của developer có thể chạy nhất quán trên máy của tester, trên server production, hay trên bất kỳ cloud nào có hỗ trợ container. Docker đã giải quyết triệt để bài toán "It works on my machine".
- Hiệu quả tài nguyên: Hàng trăm container có thể chạy trên một máy chủ mà một VM chỉ chạy được vài chục.
Docker đã tạo ra một cuộc cách mạng, giúp các developer dễ dàng đóng gói ứng dụng của họ và các Ops team dễ dàng triển khai chúng. Tuy nhiên, khi số lượng container tăng lên hàng trăm, hàng nghìn, một loạt câu hỏi mới nảy sinh:
- Làm thế nào để triển khai và cập nhật hàng trăm container một cách tự động?
- Nếu một container chết, làm thế nào để tự động khởi động lại nó?
- Làm thế nào để các container có thể giao tiếp với nhau một cách an toàn và tin cậy?
- Làm thế nào để co giãn (scale) số lượng container lên hoặc xuống tùy theo tải?
- Làm thế nào để cân bằng tải (load balancing) giữa các container?
Đây chính là lúc thế giới cần đến một hệ thống điều phối container (Container Orchestration System).
1.3. Sự ra đời của Kubernetes: Kế thừa từ Google Borg
Google là một trong những công ty đầu tiên trên thế giới vận hành ứng dụng trên quy mô cực lớn bằng công nghệ container. Trong hơn một thập kỷ, họ đã phát triển và sử dụng một hệ thống nội bộ tên là Borg để quản lý hàng tỷ container mỗi tuần.
Năm 2014, nhận thấy xu hướng container hóa đang bùng nổ và nhu cầu cấp thiết về một hệ thống điều phối mạnh mẽ, một nhóm kỹ sư tại Google đã quyết định xây dựng một phiên bản mã nguồn mở lấy cảm hứng từ Borg. Dự án đó được đặt tên là Kubernetes (tiếng Hy Lạp có nghĩa là "người lái tàu" hoặc "hoa tiêu").
Kubernetes không phải là một bản sao của Borg, nhưng nó thừa hưởng những bài học và triết lý thiết kế quý giá đã được kiểm chứng qua thực tế tại Google:
- Kiến trúc API-centric: Mọi thứ trong Kubernetes đều là một đối tượng API, cho phép khả năng tự động hóa và mở rộng gần như vô hạn.
- Trạng thái mong muốn (Desired State): Người dùng chỉ cần khai báo "trạng thái cuối cùng" họ muốn (ví dụ: "tôi muốn chạy 3 bản sao của ứng dụng web này"), và Kubernetes sẽ tự động làm mọi thứ cần thiết để đạt được và duy trì trạng thái đó.
- Khả năng tự phục hồi (Self-healing): Kubernetes liên tục theo dõi và tự động thay thế các container bị lỗi, đảm bảo ứng dụng luôn hoạt động.
- Khả năng mở rộng và di động: Kubernetes được thiết kế để chạy trên mọi môi trường, từ máy tính cá nhân, trung tâm dữ liệu riêng (on-premise) cho đến mọi nhà cung cấp đám mây công cộng (public cloud).
1.4. Kubernetes giải quyết bài toán gì? (Container Orchestration)
Về cốt lõi, Kubernetes là một nền tảng điều phối container mã nguồn mở, giúp tự động hóa việc triển khai, co giãn và quản lý các ứng dụng được container hóa.
Hãy coi Kubernetes như một "hệ điều hành cho trung tâm dữ liệu" của bạn. Thay vì bạn phải quan tâm đến từng máy chủ riêng lẻ, bạn chỉ cần giao "container ứng dụng" của mình cho Kubernetes và yêu cầu nó chạy. Kubernetes sẽ lo phần còn lại:
- Lập lịch (Scheduling): Tìm một máy chủ (Node) phù hợp trong cụm (Cluster) để chạy container của bạn.
- Quản lý vòng đời (Lifecycle Management): Tự động khởi động lại container nếu nó gặp sự cố.
- Co giãn (Scaling): Tự động tăng hoặc giảm số lượng container chạy ứng dụng của bạn dựa trên nhu_cầu.
- Khám phá dịch vụ và Cân bằng tải (Service Discovery & Load Balancing): Cung cấp một cách ổn định để các container có thể tìm thấy và giao tiếp với nhau, đồng thời phân phối lưu lượng truy cập đến chúng.
- Cập nhật và Rollback (Automated Rollouts & Rollbacks): Cho phép bạn cập nhật ứng dụng của mình mà không gây gián đoạn dịch vụ (zero-downtime) và dễ dàng quay trở lại phiên bản trước nếu có lỗi.
- Quản lý lưu trữ (Storage Orchestration): Tự động gắn các hệ thống lưu trữ khác nhau (từ local disk đến cloud storage) vào container của bạn.
- Quản lý cấu hình và bí mật (Configuration & Secret Management): Cho phép bạn lưu trữ và quản lý thông tin cấu hình và dữ liệu nhạy cảm mà không cần phải xây dựng lại image.
Đối với Developer, Kubernetes trừu tượng hóa đi sự phức tạp của hạ tầng. Bạn không cần biết ứng dụng của mình đang chạy trên máy chủ vật lý nào, địa chỉ IP của nó là gì. Bạn chỉ cần tập trung vào việc viết code và đóng gói nó vào container. Kubernetes sẽ đảm bảo ứng dụng của bạn được chạy một cách đáng tin cậy và hiệu quả.
1.5. So sánh Kubernetes với các đối thủ: Docker Swarm, Mesos
Trong những ngày đầu của cuộc chiến điều phối container, Kubernetes có hai đối thủ chính:
- Docker Swarm: Được phát triển bởi chính Docker Inc., Swarm có ưu điểm là cực kỳ dễ sử dụng và tích hợp chặt chẽ với hệ sinh thái Docker. Tuy nhiên, nó thiếu đi sự linh hoạt, khả năng mở rộng và các tính năng nâng cao mà Kubernetes cung cấp. Cộng đồng của Swarm cũng nhỏ hơn nhiều.
- Apache Mesos (với Marathon): Mesos là một "kernel quản lý tài nguyên" tổng quát hơn, có thể điều phối không chỉ container mà cả các loại workload khác (như Hadoop, Spark). Marathon là một framework chạy trên Mesos để điều phối container. Mesos rất mạnh mẽ và được sử dụng bởi các công ty lớn như Twitter, Apple, nhưng nó phức tạp hơn đáng kể để cài đặt và vận hành so với Kubernetes.
Cuối cùng, Kubernetes đã giành chiến thắng gần như tuyệt đối trong cuộc chiến này vì những lý do sau:
- Cộng đồng lớn mạnh: Được hậu thuẫn bởi Google và sau đó là Cloud Native Computing Foundation (CNCF), Kubernetes có một cộng đồng phát triển và người dùng đông đảo, năng động bậc nhất thế giới.
- Hệ sinh thái phong phú: Hàng ngàn công cụ và dịch vụ được xây dựng xung quanh Kubernetes, từ monitoring, logging, security đến CI/CD.
- Hỗ trợ từ các nhà cung cấp lớn: Mọi nhà cung cấp đám mây lớn (AWS, Google Cloud, Azure) đều cung cấp các dịch vụ Kubernetes được quản lý (Managed Kubernetes Services), giúp việc triển khai và vận hành trở nên dễ dàng hơn bao giờ hết.
- Kiến trúc mạnh mẽ và linh hoạt: Kiến trúc dựa trên API của Kubernetes cho phép nó trở thành một nền tảng cực kỳ linh hoạt và có thể mở rộng.
Ngày nay, Kubernetes đã trở thành tiêu chuẩn de facto (tiêu chuẩn thực tế) cho việc điều phối container.
1.6. Hệ sinh thái Kubernetes: CNCF và các dự án liên quan
Kubernetes không chỉ là một dự án đơn lẻ. Nó là trung tâm của một hệ sinh thái khổng lồ được quản lý bởi Cloud Native Computing Foundation (CNCF), một phần của Linux Foundation.
CNCF là ngôi nhà của hàng loạt các dự án mã nguồn mở quan trọng, được gọi là các dự án "cloud-native", được thiết kế để bổ sung và hoàn thiện cho Kubernetes. Khi làm việc với Kubernetes, bạn sẽ thường xuyên bắt gặp các dự án này:
- Container Runtime:
containerd(dự án tốt nghiệp CNCF),CRI-O. - Monitoring:
Prometheus(dự án tốt nghiệp CNCF). - Logging:
Fluentd(dự án tốt nghiệp CNCF). - Service Mesh:
Istio,Linkerd(dự án tốt nghiệp CNCF). - Service Discovery:
CoreDNS(dự án tốt nghiệp CNCF). - Storage:
Rook(dự án tốt nghiệp CNCF),Ceph. - Security:
Falco(dự án tốt nghiệp CNCF). - CI/CD & GitOps:
ArgoCD,Flux. - Package Manager:
Helm.
Việc Kubernetes trở thành một dự án của CNCF đảm bảo rằng nó sẽ luôn là một nền tảng trung lập, không bị chi phối bởi bất kỳ công ty nào và được phát triển vì lợi ích của cộng đồng.
Kết luận Chương 1: Chúng ta đã đi qua một hành trình dài, từ những máy chủ vật lý đến máy ảo và cuối cùng là sự bùng nổ của container. Kubernetes ra đời không phải là một sự tình cờ, mà là một giải pháp tất yếu cho những thách thức của việc quản lý ứng dụng container hóa ở quy mô lớn. Với kiến trúc mạnh mẽ, cộng đồng đông đảo và một hệ sinh thái phong phú, Kubernetes đã và đang định hình tương lai của ngành phát triển và vận hành phần mềm. Trong chương tiếp theo, chúng ta sẽ mổ xẻ kiến trúc bên trong của "con tàu" Kubernetes để hiểu cách nó hoạt động.
Chương 2: Kiến Trúc Tổng Quan của Kubernetes
Nếu ví Kubernetes như một dàn nhạc giao hưởng, thì kiến trúc của nó chính là cách các nhạc công và nhạc trưởng được sắp xếp để cùng nhau tạo nên một bản nhạc hoàn hảo. Hiểu rõ kiến trúc này là chìa khóa để làm chủ Kubernetes, giúp bạn chẩn đoán lỗi và thiết kế ứng dụng một cách hiệu quả.
2.1. Mô hình Master-Node (Control Plane & Data Plane)
Một cụm Kubernetes (Kubernetes Cluster) bao gồm một tập hợp các máy chủ được gọi là Nodes. Các node này được chia thành hai vai trò chính, tạo nên một mô hình chủ-tớ (master-worker) kinh điển:
Control Plane (Mặt phẳng điều khiển - trước đây gọi là Master Nodes): Đây là bộ não của cluster. Nó đưa ra mọi quyết định toàn cục về cluster (ví dụ: lập lịch cho ứng dụng), cũng như phát hiện và phản ứng với các sự kiện của cluster. Các thành phần của Control Plane có thể chạy trên cùng một máy chủ hoặc được phân tán trên nhiều máy chủ để đảm bảo tính sẵn sàng cao (High Availability - HA).
Data Plane (Mặt phẳng dữ liệu - hay Worker Nodes): Đây là nơi các ứng dụng của bạn thực sự chạy. Mỗi Worker Node là một máy chủ (vật lý hoặc ảo) có trách nhiệm chạy các Pods, đơn vị chứa các container ứng dụng. Worker Node nhận lệnh từ Control Plane và thực thi chúng.
Sự phân tách này rất quan trọng:
- Tập trung quản lý: Control Plane là điểm trung tâm duy nhất để quản lý và cấu hình toàn bộ cluster.
- Tách biệt workload: Ứng dụng của người dùng không chạy trên Control Plane, giúp bảo vệ các thành phần cốt lõi khỏi các lỗi ứng dụng tiềm tàng.
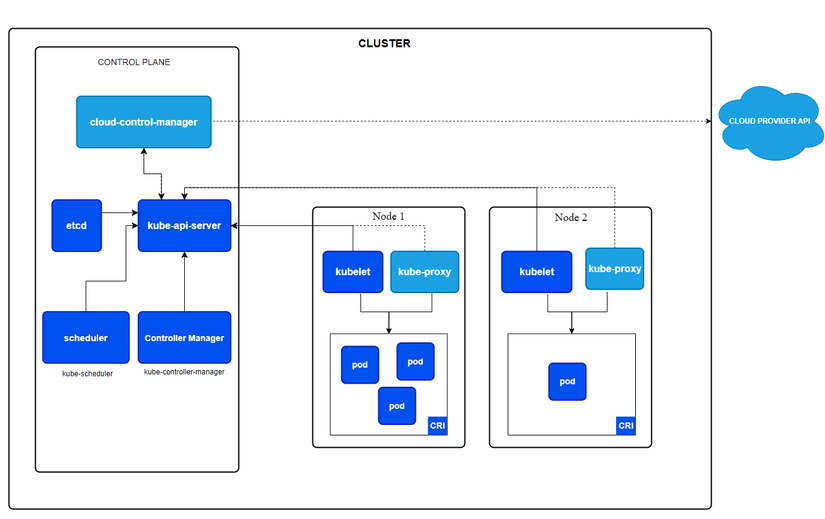
Bây giờ, hãy cùng "mổ xẻ" từng thành phần bên trong hai mặt phẳng này.
2.2. Các thành phần của Control Plane
Control Plane bao gồm các tiến trình (process) cốt lõi điều khiển hoạt động của Kubernetes.
2.2.1. kube-apiserver (API Server)
- Vai trò: Là cửa ngõ (gateway) và trung tâm thần kinh của Control Plane. Mọi tương tác với cluster, dù đến từ người dùng (qua
kubectl), từ các thành phần khác trong cluster, hay từ các công cụ bên ngoài, đều phải đi quakube-apiserver. - Chức năng chính:
- Phơi bày Kubernetes API: Cung cấp một giao diện RESTful API cho phép người dùng và các thành phần khác truy vấn và thay đổi trạng thái của các đối tượng trong cluster (như Pods, Services, Deployments).
- Xác thực và Ủy quyền (Authentication & Authorization): Kiểm tra xem ai đang thực hiện yêu cầu và họ có quyền làm điều đó hay không.
- Kiểm soát truy cập (Admission Control): Thực thi các quy tắc bổ sung trước khi một đối tượng được tạo hoặc sửa đổi (ví dụ: đảm bảo mọi container đều có
resource limits). - Giao tiếp với
etcd: Là thành phần duy nhất được phép nói chuyện trực tiếp vớietcdđể đọc và ghi trạng thái của cluster.
Góc nhìn Developer: Khi bạn gõ lệnh
kubectl get pods, thực chấtkubectlđang gửi một yêu cầu HTTP GET đếnkube-apiserver. API Server sau đó xác thực bạn, truy vấnetcdđể lấy danh sách Pods, và trả kết quả về chokubectl.
2.2.2. etcd
- Vai trò: Là kho lưu trữ key-value nhất quán và có tính sẵn sàng cao, đóng vai trò là nguồn chân lý duy nhất (single source of truth) cho toàn bộ cluster.
- Chức năng chính:
- Lưu trữ toàn bộ trạng thái của cluster, bao gồm cấu hình, trạng thái hiện tại và trạng thái mong muốn của tất cả các đối tượng (Pods, Secrets, ConfigMaps, Deployments, v.v.).
- Sử dụng thuật toán đồng thuận Raft để đảm bảo dữ liệu luôn nhất quán trên tất cả các node
etcdtrong một cluster HA.
Góc nhìn Developer: Bạn gần như không bao giờ tương tác trực tiếp với
etcd. Hãy coi nó như một "cơ sở dữ liệu nội bộ" của Kubernetes. Mất dữ liệuetcdđồng nghĩa với việc mất toàn bộ trạng thái của cluster, một thảm họa thực sự.
2.2.3. kube-scheduler
- Vai trò: Là người điều phối tài nguyên. Nó có một nhiệm vụ duy nhất: tìm một Worker Node phù hợp nhất để chạy một Pod mới được tạo.
- Chức năng chính:
- Theo dõi các Pod mới được tạo nhưng chưa được gán cho Node nào.
- Đối với mỗi Pod, nó sẽ lọc ra danh sách các Node có thể chạy được Pod đó dựa trên các yêu cầu (ví dụ: yêu cầu CPU/Memory,
node affinity,taints and tolerations, v.v.). - Sau khi lọc, nó sẽ "chấm điểm" các Node phù hợp và chọn ra Node có điểm cao nhất để chạy Pod.
- Cuối cùng, nó thông báo cho
kube-apiservervề quyết định của mình.
Góc nhìn Developer: Bạn có thể ảnh hưởng đến quyết định của Scheduler bằng cách chỉ định
requestsvàlimitscho Pod, hoặc sử dụng các cơ chế lập lịch nâng cao nhưnodeSelector,affinity, vàtolerationsđể kiểm soát vị trí Pod của mình sẽ chạy.
2.2.4. kube-controller-manager (Controller Manager)
- Vai trò: Là một cỗ máy chạy các vòng lặp điều khiển (control loops). Nó liên tục so sánh trạng thái mong muốn (được lưu trong
etcd) với trạng thái thực tế của cluster và thực hiện các hành động cần thiết để đưa thực tế về đúng với mong muốn. - Chức năng chính:
- Thực chất,
kube-controller-managerlà một tiến trình duy nhất gộp nhiều controller khác nhau để giảm sự phức tạp. Mỗi controller chịu trách nhiệm cho một loại tài nguyên cụ thể. - Node Controller: Chịu trách nhiệm phát hiện và phản ứng khi một Node "chết".
- Replication Controller (một phần của Deployment Controller): Đảm bảo số lượng Pod mong muốn cho một
ReplicaSetluôn được duy trì. - Endpoints Controller: Điền thông tin vào đối tượng Endpoints (tức là danh sách IP của các Pod) cho một
Service. - Service Account & Token Controller: Tạo
ServiceAccountvà token API mặc định cho các Namespace mới. - Và nhiều controller khác...
- Thực chất,
Góc nhìn Developer: Khi bạn tạo một
Deploymentvớireplicas: 3, chínhDeployment Controller(bên trongkube-controller-manager) sẽ phát hiện ra điều này. Nó sẽ tạo mộtReplicaSet, và sau đóReplicaSet Controllersẽ thấy rằng nó cần 3 Pod nhưng thực tế đang có 0, vì vậy nó sẽ yêu cầu tạo 3 Pod mới. Đây là ví dụ kinh điển về nguyên lý "trạng thái mong muốn".
2.2.5. cloud-controller-manager (Tùy chọn)
- Vai trò: Tách biệt logic tương tác với nhà cung cấp đám mây cụ thể ra khỏi lõi của Kubernetes.
- Chức năng chính:
- Chạy các controller chuyên biệt cho từng cloud (AWS, GCP, Azure, v.v.).
- Node Controller (Cloud): Kiểm tra xem một Node đã bị xóa khỏi cloud chưa.
- Route Controller: Cấu hình route trong hạ tầng mạng của cloud.
- Service Controller: Tạo, cập nhật và xóa các Load Balancer của cloud khi bạn tạo một
ServiceloạiLoadBalancer.
Góc nhìn Developer: Thành phần này giúp Kubernetes trở nên "cloud-agnostic". Cùng một file YAML để tạo
ServiceloạiLoadBalancersẽ hoạt động trên cả AWS, GCP và Azure, vìcloud-controller-managersẽ tự động "dịch" yêu cầu đó thành các lệnh gọi API tương ứng của từng cloud.
2.3. Các thành phần của Worker Node
Worker Node là nơi thực thi công việc. Mỗi Worker Node chạy các thành phần sau:
2.3.1. kubelet
- Vai trò: Là "đại sứ" của Control Plane tại mỗi Worker Node. Nó là một agent chạy trên mỗi Node và đảm bảo rằng các container được mô tả trong các PodSpec (thông số kỹ thuật của Pod) đang thực sự chạy và khỏe mạnh.
- Chức năng chính:
- Đăng ký Node với
kube-apiserver. - Theo dõi
kube-apiserverđể xem có Pod nào được lập lịch cho Node của nó không. - Yêu cầu
Container Runtime(ví dụ:containerd) kéo image và chạy container. - Liên tục theo dõi trạng thái của các container và báo cáo lại cho
kube-apiserver. - Thực hiện các
livenessvàreadiness probesđể kiểm tra sức khỏe của container.
- Đăng ký Node với
Góc nhìn Developer:
kubeletlà lý do tại sao Pod của bạn được chạy. Nếukubelettrên một Node ngừng hoạt động, Control Plane sẽ coi Node đó làNotReadyvà sẽ không lập lịch thêm Pod nào cho nó.
2.3.2. kube-proxy
- Vai trò: Là nhạc trưởng của mạng lưới trên mỗi Node. Nó chịu trách nhiệm cho việc networking của các
Service. - Chức năng chính:
- Duy trì các quy tắc mạng trên Node, cho phép giao tiếp mạng đến các Pod của bạn từ bên trong hoặc bên ngoài cluster.
- Nó theo dõi
kube-apiserverđể biết các thay đổi vềServicevàEndpoints. - Đối với mỗi
Service, nó sẽ cài đặt các quy tắc (sử dụngiptables,IPVS, hoặceBPF) để chuyển tiếp lưu lượng truy cập đến đúng các Pod backend.
Góc nhìn Developer: Khi Pod A của bạn gọi đến một
ServiceB, chínhkube-proxyđã thiết lập các quy tắc để "bắt" gói tin đó và chuyển nó đến một trong các Pod thực sự của Service B. Bạn không cần quan tâm đến địa chỉ IP thực của các Pod, chỉ cần gọi đến tên củaService.
2.3.3. Container Runtime
- Vai trò: Là động cơ chịu trách nhiệm thực thi các container.
- Chức năng chính:
- Kéo container image từ registry.
- Khởi chạy và dừng container.
- Kubernetes hỗ trợ nhiều container runtime khác nhau thông qua một chuẩn giao tiếp gọi là Container Runtime Interface (CRI).
- Các runtime phổ biến bao gồm:
containerd: Một runtime tiêu chuẩn công nghiệp, được tách ra từ dự án Docker và hiện là một dự án của CNCF. Đây là runtime mặc định cho hầu hết các dịch vụ Kubernetes được quản lý.CRI-O: Một runtime nhẹ được tạo ra chuyên biệt cho Kubernetes.- Docker Engine: Trước đây là runtime mặc định, nhưng từ phiên bản Kubernetes 1.24,
dockershim(lớp tương thích) đã bị loại bỏ, và người dùng được khuyến khích chuyển sangcontainerdhoặcCRI-O.
Góc nhìn Developer: Mặc dù bạn có thể xây dựng image bằng Docker, nhưng khi chạy trên một cluster Kubernetes hiện đại, rất có thể image đó đang được thực thi bởi
containerdchứ không phải Docker Engine.
2.4. Luồng hoạt động của một yêu cầu: Từ kubectl đến khi Pod được tạo
Để tổng kết lại, hãy xem điều gì xảy ra khi bạn chạy lệnh kubectl run my-app --image=nginx:
kubectlchuyển đổi lệnh của bạn thành một file YAML mô tả mộtDeploymentvà gửi một yêu cầu POST đếnkube-apiserver.kube-apiservernhận yêu cầu, xác thực bạn, và ghi đối tượngDeploymentmới vàoetcd.kube-controller-manager(cụ thể làDeployment Controller) phát hiện cóDeploymentmới. Nó tạo mộtReplicaSettương ứng và ghi vàoetcd.kube-controller-manager(cụ thể làReplicaSet Controller) phát hiện cóReplicaSetmới. Nó thấy rằng trạng thái mong muốn là 1 Pod nhưng thực tế là 0, vì vậy nó tạo một đối tượngPodvà ghi vàoetcd.kube-schedulerphát hiện có mộtPodmới chưa được gán cho Node nào. Nó thực hiện thuật toán lọc và chấm điểm, sau đó quyết định chạy Pod này trênWorker-Node-2. Nó cập nhật thông tin này vào đối tượngPodtrongetcd.kubelettrênWorker-Node-2(vốn luôn theo dõi API Server) thấy rằng có một Pod mới được gán cho nó.kubeletđọc thông số của Pod (cần chạy imagenginx) và yêu cầuContainer Runtime(containerd) kéo imagenginxvà khởi chạy container.Container Runtimetạo và chạy container.kubeletbáo cáo lại trạng thái "Pod đang chạy" chokube-apiserver, và trạng thái này được cập nhật vàoetcd.
Lúc này, Pod của bạn đã hoạt động! Toàn bộ quá trình này diễn ra tự động và thường chỉ mất vài giây.
Kết luận Chương 2: Chúng ta đã khám phá bộ máy phức tạp nhưng được thiết kế tuyệt vời của Kubernetes. Mỗi thành phần, từ kube-apiserver đến kubelet, đều có một vai trò rõ ràng và phối hợp nhịp nhàng với nhau dựa trên nguyên tắc "trạng thái mong muốn". Hiểu được kiến trúc này không chỉ giúp bạn sử dụng Kubernetes hiệu quả hơn mà còn là nền tảng để khám phá các khái niệm cốt lõi sẽ được trình bày trong các chương tiếp theo.
Chương 3: Cài Đặt Môi Trường và Công Cụ Thiết Yếu
Lý thuyết là nền tảng, nhưng thực hành mới tạo nên một chuyên gia. Trong chương này, chúng ta sẽ "xắn tay áo lên", cài đặt các công cụ cần thiết và dựng lên một môi trường Kubernetes ngay trên máy tính của bạn. Đây là bước cực kỳ quan trọng để bạn có thể tự mình thử nghiệm, khám phá và vận hành các ví dụ trong suốt cuốn sách này.
3.1. kubectl: Giao tiếp với Kubernetes Cluster
kubectl (phát âm là "kube control" hoặc "kube C-T-L") là công cụ dòng lệnh (CLI) chính thức và không thể thiếu để tương tác với một Kubernetes cluster. Nó hoạt động như một chiếc điều khiển từ xa, cho phép bạn ra lệnh cho cluster, triển khai ứng dụng, kiểm tra và quản lý tài nguyên, xem log, và nhiều hơn thế nữa.
3.1.1. Cài đặt và cấu hình kubectl
Việc cài đặt kubectl khá đơn giản. Bạn có thể tải bản thực thi (binary) phù hợp với hệ điều hành của mình từ tài liệu chính thức của Kubernetes.
- Trên macOS:bash
# Sử dụng Homebrew (khuyến khích) brew install kubectl - Trên Windows:powershell
# Sử dụng Chocolatey hoặc Scoop (khuyến khích) choco install kubernetes-cli # hoặc scoop install kubectl - Trên Linux:bash
# Ví dụ cho Debian/Ubuntu sudo apt-get update sudo apt-get install -y apt-transport-https ca-certificates curl curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.28/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.28/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list sudo apt-get update sudo apt-get install -y kubectl
Sau khi cài đặt, kubectl cần một file cấu hình để biết phải kết nối đến cluster nào. File này thường được gọi là kubeconfig và mặc định được lưu tại ~/.kube/config.
Khi bạn sử dụng các công cụ như Minikube, Docker Desktop, hoặc khi bạn cấu hình truy cập đến một cluster trên cloud (GKE, EKS, AKS), chúng sẽ tự động tạo hoặc cập nhật file kubeconfig này cho bạn.
Một vài lệnh hữu ích để quản lý cấu hình:
# Xem cấu hình hiện tại
kubectl config view
# Liệt kê tất cả các "context" (các cluster bạn có thể kết nối)
kubectl config get-contexts
# Xem context hiện tại đang sử dụng
kubectl config current-context
# Chuyển đổi sang một context khác
kubectl config use-context <tên-context>3.1.2. Các lệnh kubectl cơ bản và cần thiết nhất
Dưới đây là danh sách các lệnh kubectl mà bất kỳ developer nào cũng phải thuộc nằm lòng. Chúng được nhóm theo chức năng để bạn dễ theo dõi.
1. Lệnh kiểm tra (Inspecting Resources):
kubectl get <loại-tài-nguyên> [tên-tài-nguyên]: Lấy thông tin cơ bản về tài nguyên.kubectl get pods: Liệt kê tất cả Pods trong namespace hiện tại.kubectl get nodes: Liệt kê tất cả các Node trong cluster.kubectl get services,ingresses -n production: Liệt kê Services và Ingresses trong namespaceproduction.kubectl get pod my-pod-123 -o yaml: Lấy định nghĩa YAML đầy đủ của một Pod cụ thể.
kubectl describe <loại-tài-nguyên> <tên-tài-nguyên>: Hiển thị thông tin chi tiết, bao gồm các sự kiện (Events) liên quan đến tài nguyên. Cực kỳ hữu ích để debug.kubectl describe pod my-pod-123: Xem chi tiết tại sao Pod không chạy, các sự kiện gần đây, v.v.
kubectl logs <tên-pod>: Xem log của một Pod.kubectl logs -f my-pod-123: Theo dõi log (stream) của Pod.kubectl logs my-multi-container-pod -c my-sidecar: Xem log của một container cụ thể trong Pod đa container.
2. Lệnh tạo và áp dụng (Creating & Applying):
kubectl apply -f <tên-file.yaml>: Tạo hoặc cập nhật tài nguyên từ một file hoặc thư mục YAML. Đây là lệnh được khuyến khích sử dụng nhất vì tính khai báo (declarative) của nó.kubectl create <loại-tài-nguyên> <tên> [cờ]: Tạo tài nguyên một cách mệnh lệnh (imperative). Hữu ích cho việc tạo nhanh hoặc trong script.kubectl create namespace my-namespace: Tạo một namespace mới.
kubectl run <tên-pod> --image=<tên-image>: Tạo nhanh một Pod để chạy một image (lưu ý: trong các phiên bản cũ, lệnh này tạo Deployment, nhưng giờ nó tạo Pod).
3. Lệnh sửa đổi và xóa (Modifying & Deleting):
kubectl edit <loại-tài-nguyên> <tên>: Mở trình soạn thảo mặc định để sửa đổi trực tiếp định nghĩa của một tài nguyên.kubectl scale deployment <tên-deployment> --replicas=<số-lượng>: Co giãn số lượng replica của một Deployment.kubectl delete -f <tên-file.yaml>: Xóa các tài nguyên được định nghĩa trong file.kubectl delete <loại-tài-nguyên> <tên>: Xóa một tài nguyên cụ thể.
4. Lệnh gỡ lỗi (Debugging):
kubectl exec -it <tên-pod> -- /bin/bash: Mở một shell tương tác bên trong một container đang chạy. Vô giá để kiểm tra môi trường, file hệ thống, hoặc kết nối mạng từ bên trong Pod.kubectl port-forward <tên-pod> <port-máy-local>:<port-pod>: Chuyển tiếp một port từ máy local của bạn vào một Pod. Giúp bạn truy cập ứng dụng đang chạy trong Pod như thể nó đang chạy trênlocalhost.kubectl port-forward my-web-pod 8080:80
3.1.3. Mẹo và thủ thuật với kubectl
- Bật tự động hoàn thành (Autocomplete): Giúp bạn gõ lệnh nhanh và chính xác hơn. Hãy làm theo hướng dẫn chính thức để cài đặt cho shell của bạn (bash, zsh, ...).
- Đặt bí danh (Alias): Hầu hết mọi người đều đặt bí danh
kchokubectl.bash# Thêm vào file .bashrc hoặc .zshrc alias k=kubectl - Sử dụng Plugin với
krew:krewlà trình quản lý plugin chokubectl. Nó cho phép bạn cài đặt và sử dụng các plugin hữu ích từ cộng đồng.krew install ns: Plugin để chuyển đổi namespace nhanh chóng (kubectl ns <tên-namespace>).krew install view-utilization: Xem mức độ sử dụng tài nguyên của các node.
- Định dạng đầu ra: Sử dụng cờ
-o(hoặc--output) để thay đổi định dạng.-o wide: Hiển thị thêm thông tin (ví dụ: IP của Pod, Node đang chạy).-o yamlhoặc-o json: Hiển thị định nghĩa đầy đủ của tài nguyên.-o jsonpath='{.spec.containers[0].image}': Trích xuất một trường cụ thể từ JSON.
3.2. Xây dựng một Kubernetes Cluster cục bộ cho Developer
Để học và phát triển với Kubernetes, bạn không cần một cluster "xịn" trên cloud. Có rất nhiều công cụ tuyệt vời giúp bạn chạy một cluster Kubernetes đầy đủ chức năng ngay trên máy tính xách tay của mình.
3.2.1. Minikube
- Là gì: Minikube là công cụ lâu đời và phổ biến nhất để chạy một cluster Kubernetes một node bên trong một máy ảo (VM) hoặc container.
- Ưu điểm:
- Rất dễ cài đặt và sử dụng.
- Hỗ trợ nhiều "driver" (VirtualBox, Hyper-V, Docker) để chạy cluster.
- Tích hợp các "addon" dễ dàng (ví dụ:
minikube addons enable ingress).
- Nhược điểm:
- Mặc định chỉ là một node, hạn chế cho việc thử nghiệm các tính năng liên quan đến đa node.
- Lệnh cơ bản:bash
# Bắt đầu một cluster minikube start --driver=docker # Dừng cluster minikube stop # Xóa cluster minikube delete
3.2.2. Kind (Kubernetes in Docker)
- Là gì: Kind là một công cụ sử dụng các container Docker để chạy các "node" Kubernetes. Mỗi node trong cluster Kind thực chất là một container Docker.
- Ưu điểm:
- Khởi động cực kỳ nhanh.
- Dễ dàng tạo cluster đa node để mô phỏng môi trường production gần hơn.
- Rất phù hợp cho các kịch bản CI/CD vì tính gọn nhẹ.
- Nhược điểm:
- Phụ thuộc vào Docker.
- Lệnh cơ bản:bash
# Tạo một cluster mặc định kind create cluster # Tạo một cluster với tên cụ thể kind create cluster --name my-cluster # Xóa cluster kind delete cluster --name my-cluster
3.2.3. Docker Desktop Kubernetes
- Là gì: Nếu bạn đã cài đặt Docker Desktop (trên Windows hoặc macOS), nó đi kèm với một tùy chọn để bật một cluster Kubernetes chỉ bằng một cú nhấp chuột.
- Ưu điểm:
- Không cần cài đặt thêm gì nếu đã có Docker Desktop.
- Cực kỳ tiện lợi, chỉ cần một checkbox để bật/tắt.
- Tích hợp chặt chẽ với Docker Desktop.
- Nhược điểm:
- Chỉ là cluster một node.
- Ít tùy chỉnh hơn so với Minikube hay Kind.
- Cách bật: Mở Settings/Preferences của Docker Desktop -> Chọn tab Kubernetes -> Tích vào ô "Enable Kubernetes".
3.2.4. So sánh và lựa chọn công cụ phù hợp
| Tiêu chí | Minikube | Kind | Docker Desktop |
|---|---|---|---|
| Độ dễ sử dụng | Cao | Trung bình | Rất cao |
| Tốc độ khởi động | Trung bình | Rất nhanh | Nhanh |
| Hỗ trợ đa node | Có (phức tạp hơn) | Rất tốt | Không |
| Tài nguyên tiêu thụ | Trung bình-Cao | Thấp-Trung bình | Trung bình |
| Tùy chỉnh | Cao | Rất cao | Thấp |
| Trường hợp nên dùng | Người mới bắt đầu, cần sự ổn định và nhiều addon. | Cần cluster đa node, CI/CD, khởi động nhanh. | Đã có Docker Desktop, cần sự tiện lợi tối đa. |
Khuyến nghị cho Developer: Bắt đầu với Docker Desktop nếu bạn đã có sẵn. Khi bạn cần thử nghiệm các kịch bản phức tạp hơn liên quan đến nhiều node, hãy chuyển sang Kind.
3.3. Các công cụ hỗ trợ khác
Ngoài kubectl, hệ sinh thái Kubernetes còn có rất nhiều công cụ đồ họa và dòng lệnh giúp công việc của bạn trở nên dễ dàng và hiệu quả hơn.
3.3.1. k9s
- Là gì: Một giao diện người dùng trên terminal (TUI) để quản lý Kubernetes. Nó cho phép bạn điều hướng, quan sát và quản lý cluster của mình một cách cực kỳ nhanh chóng mà không cần rời khỏi terminal.
- Tại sao nên dùng:
- Tốc độ: Nhanh hơn nhiều so với việc gõ hàng loạt lệnh
kubectl. - Trực quan: Hiển thị tài nguyên, mối quan hệ giữa chúng, và trạng thái một cách rõ ràng.
- Tích hợp sẵn các lệnh thường dùng: Dễ dàng xem log, shell vào Pod, xóa, sửa tài nguyên chỉ bằng vài phím tắt.
- Chế độ "Pulse" để theo dõi sức khỏe cluster theo thời gian thực.
- Tốc độ: Nhanh hơn nhiều so với việc gõ hàng loạt lệnh
3.3.2. Lens
- Là gì: Một ứng dụng desktop (IDE cho Kubernetes) cung cấp một giao diện đồ họa (GUI) mạnh mẽ để quản lý một hoặc nhiều cluster.
- Tại sao nên dùng:
- Quản lý đa cluster: Dễ dàng chuyển đổi và quản lý nhiều cluster từ một nơi duy nhất.
- Trực quan hóa mạnh mẽ: Hiển thị tài nguyên, biểu đồ sử dụng CPU/Memory, các sự kiện một cách chi tiết.
- Tích hợp sẵn Prometheus: Tự động phát hiện và hiển thị các metric từ Prometheus nếu có.
- Chợ ứng dụng (Apps Marketplace): Dễ dàng cài đặt hàng trăm ứng dụng phổ biến (như Prometheus, Grafana, Nginx Ingress) chỉ bằng vài cú nhấp chuột.
Kết luận Chương 3: Chúng ta đã trang bị cho mình bộ công cụ cần thiết: kubectl để ra lệnh, một cluster Kubernetes cục bộ (Minikube, Kind, hoặc Docker Desktop) để thực hành, và các công cụ hỗ trợ như k9s và Lens để tăng năng suất. Với môi trường đã sẵn sàng, bạn đã có thể bắt đầu hành trình khám phá các khái niệm cốt lõi của Kubernetes. Trong chương tiếp theo, chúng ta sẽ tìm hiểu về "viên gạch" cơ bản nhất của mọi ứng dụng trên Kubernetes: Pod.
Phần II: Các Khái Niệm Cốt Lõi trong Kubernetes
Chương 4: Pod - Đơn Vị Nhỏ Nhất
Nếu container là các diễn viên, thì Pod chính là sân khấu nơi họ biểu diễn. Trong thế giới Kubernetes, chúng ta không trực tiếp quản lý các container riêng lẻ. Thay vào đó, chúng ta làm việc với một lớp trừu tượng cao hơn gọi là Pod. Đây là khái niệm cơ bản nhất và quan trọng nhất mà mọi developer cần nắm vững.
4.1. Pod là gì? Tại sao không phải là Container?
Một Pod là đơn vị nhỏ nhất có thể triển khai và quản lý trong Kubernetes. Về cơ bản, một Pod là một nhóm gồm một hoặc nhiều container được triển khai cùng nhau trên cùng một Worker Node.
Các container bên trong một Pod có những đặc điểm chung rất quan trọng:
- Chia sẻ chung không gian mạng (Network Namespace): Tất cả các container trong cùng một Pod chia sẻ chung một địa chỉ IP và dải port. Chúng có thể giao tiếp với nhau thông qua
localhost. - Chia sẻ chung không gian lưu trữ (Storage Volumes): Các container trong Pod có thể chia sẻ chung dữ liệu thông qua các
Volumeđược định nghĩa ở cấp độ Pod. - Luôn được lập lịch cùng nhau (Co-located and Co-scheduled): Kubernetes luôn đảm bảo tất cả các container của một Pod được chạy trên cùng một Worker Node.
- Chia sẻ chung vòng đời: Khi Pod được tạo, tất cả container trong nó sẽ được tạo. Khi Pod bị xóa, tất cả container cũng bị xóa.
Vậy tại sao Kubernetes lại dùng Pod mà không dùng thẳng container?
Đây là một quyết định thiết kế thiên tài. Việc nhóm các container vào một Pod cho phép chúng ta mô hình hóa các ứng dụng một cách linh hoạt hơn. Lý do chính là để hỗ trợ các container "phụ trợ" (helper containers) có nhiệm vụ bổ sung cho container chính.
Hãy tưởng tượng bạn có một ứng dụng web (container chính). Bạn có thể muốn:
- Một container khác (sidecar) chuyên thu thập log từ ứng dụng web và gửi đến một hệ thống logging tập trung.
- Một container khác (sidecar) chuyên xử lý các yêu cầu TLS/SSL và proxy traffic đến ứng dụng web.
- Một container khác (init) chuyên tải dữ liệu cấu hình từ một nơi nào đó trước khi ứng dụng web khởi động.
Tất cả các container này có mối quan hệ rất chặt chẽ, cần được triển khai và quản lý như một đơn vị duy nhất. Chúng cần giao tiếp qua localhost và chia sẻ file. Pod chính là mô hình hoàn hảo cho kịch bản này. Nó đóng vai trò như một "máy chủ logic" nhỏ gọn cho các container có liên quan mật thiết.
Quy tắc vàng: Hầu hết thời gian, một Pod chỉ chứa một container ứng dụng chính. Chỉ sử dụng Pod đa container khi bạn có các container phụ trợ có vòng đời và phụ thuộc chặt chẽ vào container chính.
4.2. Vòng đời của Pod (Pod Lifecycle)
Một Pod không tồn tại mãi mãi. Nó được tạo ra, sống, và cuối cùng sẽ chết. Hiểu được vòng đời của nó là rất quan trọng để gỡ lỗi. Một Pod sẽ trải qua các giai đoạn (Phase) sau:
Pending(Đang chờ): Pod đã được chấp nhận bởi cluster, nhưng một hoặc nhiều container của nó chưa được tạo và chạy. Giai đoạn này bao gồm thời gian chờ Pod được lập lịch lên một Node và thời gian kéo container image.Running(Đang chạy): Pod đã được gán cho một Node, tất cả các container của nó đã được tạo. Ít nhất một container vẫn đang chạy, hoặc đang trong quá trình khởi động/khởi động lại.Succeeded(Thành công): Tất cả các container trong Pod đã kết thúc thành công (exit code 0) và sẽ không được khởi động lại. Giai đoạn này thường thấy ở các Pod được quản lý bởiJob.Failed(Thất bại): Tất cả các container trong Pod đã kết thúc, và ít nhất một container đã kết thúc với lỗi (exit code khác 0).Unknown(Không xác định): Trạng thái của Pod không thể được xác định, thường là do lỗi giao tiếp với Node nơi Pod đang chạy.
Bạn có thể xem phase của một Pod bằng lệnh kubectl get pod <tên-pod> -o wide.
Ngoài phase, Kubernetes còn theo dõi một tập hợp các điều kiện (Conditions) chi tiết hơn của Pod, như PodScheduled, Initialized, ContainersReady, và Ready. Một Pod được coi là Ready (sẵn sàng nhận traffic) chỉ khi tất cả các container của nó đều Ready và các readiness probe (sẽ học ở chương sau) đều thành công.
4.3. Cấu hình một Pod: File YAML đầu tiên của bạn
Trong Kubernetes, chúng ta định nghĩa "trạng thái mong muốn" bằng các file YAML (hoặc JSON). Đây là ngôn ngữ giao tiếp chính với Kubernetes API.
Hãy cùng tạo một file my-first-pod.yaml để định nghĩa một Pod đơn giản chạy web server Nginx:
# my-first-pod.yaml
# Phiên bản API được sử dụng để tạo đối tượng này
apiVersion: v1
# Loại đối tượng chúng ta muốn tạo
kind: Pod
# Metadata - Dữ liệu về đối tượng
metadata:
name: nginx-pod
labels:
app: nginx
# Specification - Đặc tả/Cấu hình mong muốn của đối tượng
spec:
containers:
# Danh sách các container chạy trong Pod này
- name: nginx-container
image: nginx:1.21
ports:
- containerPort: 80Hãy phân tích các trường quan trọng:
apiVersion: Xác định phiên bản API của Kubernetes mà bạn đang sử dụng. Đối với Pod, nó luôn làv1.kind: Loại đối tượng Kubernetes bạn muốn tạo. Ở đây làPod.metadata: Chứa thông tin để nhận dạng đối tượng, bao gồm:name: Tên duy nhất của Pod trong một Namespace.labels: Các cặp key-value tùy ý được gắn vào đối tượng. Labels cực kỳ quan trọng để tổ chức và lựa chọn các đối tượng (chúng ta sẽ thấy tầm quan trọng của nó khi học vềServicevàDeployment).
spec(specification): Đây là nơi bạn định nghĩa trạng thái mong muốn của Pod.containers: Một danh sách (array) các container bạn muốn chạy trong Pod.name: Tên của container.image: Tên của container image sẽ được kéo về để chạy.ports: Danh sách các port mà container sẽ mở.containerPortchỉ mang tính thông tin, nó không thực sự mở port ra bên ngoài.
Để tạo Pod này trong cluster, bạn chạy lệnh:
kubectl apply -f my-first-pod.yamlSau đó, bạn có thể kiểm tra trạng thái của nó:
kubectl get pod nginx-pod
# Hoặc chi tiết hơn
kubectl describe pod nginx-podLưu ý quan trọng: Trong thực tế, bạn rất hiếm khi tạo trực tiếp một Pod như thế này. Pod được coi là tài nguyên "dùng một lần" (ephemeral). Nếu Node chạy Pod này bị lỗi, Pod sẽ biến mất. Thay vào đó, chúng ta luôn sử dụng các Controller cấp cao hơn như Deployment hoặc StatefulSet để quản lý Pod. Các controller này sẽ đảm bảo Pod của bạn được tự động khởi động lại, co giãn và cập nhật. Tuy nhiên, hiểu rõ về đối tượng Pod là nền tảng cho mọi thứ khác.
4.4. Pod đa container (Multi-container Pods) và các mẫu thiết kế
Như đã đề cập, sức mạnh thực sự của Pod nằm ở khả năng chạy nhiều container có liên quan chặt chẽ với nhau. Điều này đã tạo ra một số mẫu thiết kế (design patterns) phổ biến.
Mẫu Sidecar: Đây là mẫu phổ biến nhất. Một container "sidecar" được thêm vào Pod để mở rộng hoặc cải thiện chức năng của container chính. Container chính không cần biết về sự tồn tại của sidecar.
- Ví dụ 1: Logging Agent:
- Container chính: Ứng dụng của bạn, ghi log vào một file trong một Volume dùng chung.
- Container sidecar: Một agent (như Fluentd, Logstash) đọc log từ Volume đó và gửi đến một hệ thống logging tập trung.
- Ví dụ 2: Service Mesh Proxy:
- Container chính: Ứng dụng microservice của bạn.
- Container sidecar: Một proxy (như Envoy, Linkerd-proxy) được tự động tiêm vào Pod. Proxy này sẽ chặn tất cả traffic vào/ra, xử lý các tác vụ như TLS, retry, circuit breaking, thu thập metrics, v.v.
Mẫu Ambassador: Container "ambassador" hoạt động như một proxy để đơn giản hóa việc giao tiếp của container chính với thế giới bên ngoài.
- Ví dụ: Container chính của bạn cần nói chuyện với một cơ sở dữ liệu có nhiều replica (1 primary, nhiều read-replica). Thay vì code logic phức tạp để quyết định kết nối đến replica nào, container chính chỉ cần kết nối đến
localhost:5432trên ambassador. Container ambassador sẽ chứa logic để tìm ra địa chỉ IP đúng của primary hoặc read-replica và proxy kết nối đến đó.
Mẫu Adapter: Container "adapter" chuẩn hóa và chuyển đổi định dạng đầu ra (output) của container chính.
- Ví dụ: Container chính là một ứng dụng cũ xuất ra log hoặc metric ở một định dạng không chuẩn. Container adapter sẽ đọc output đó, chuyển đổi nó sang một định dạng chuẩn (như định dạng của Prometheus) và phơi bày nó ra cho hệ thống monitoring.
4.5. Init Containers
Đôi khi, bạn cần thực hiện một số tác vụ khởi tạo trước khi container ứng dụng chính của bạn bắt đầu. Đây là lúc Init Containers tỏa sáng.
Init Containers là các container đặc biệt chạy tuần tự trước khi các container chính được khởi động.
- Chúng chạy lần lượt, container sau chỉ bắt đầu khi container trước kết thúc thành công.
- Nếu bất kỳ Init Container nào thất bại, Kubernetes sẽ khởi động lại Pod (dựa trên
restartPolicy) cho đến khi nó thành công. - Container ứng dụng chính sẽ chỉ bắt đầu sau khi tất cả Init Containers đã chạy xong.
Các trường hợp sử dụng phổ biến:
- Chờ một service hoặc database khác sẵn sàng trước khi khởi động.
- Tải dữ liệu cấu hình hoặc file thực thi từ một nơi nào đó vào một Volume dùng chung.
- Thực hiện các thao tác cài đặt, migration database.
- Thay đổi quyền sở hữu file trong một Volume.
Ví dụ về YAML:
apiVersion: v1
kind: Pod
metadata:
name: my-app
spec:
containers:
- name: app-container
image: my-app-image
# Init containers được định nghĩa ở đây
initContainers:
- name: wait-for-db
image: busybox:1.28
# Lệnh này sẽ ping service 'my-db' cho đến khi thành công
command: ['sh', '-c', 'until nslookup my-db; do echo waiting for my-db; sleep 2; done;']
- name: setup-files
image: busybox:1.28
command: ['sh', '-c', 'echo "Hello World" > /work-dir/hello.txt']
volumeMounts:
- name: workdir
mountPath: "/work-dir"
volumes:
- name: workdir
emptyDir: {}4.6. Static Pods
Đây là một loại Pod đặc biệt, không được quản lý bởi kube-apiserver. Thay vào đó, kubelet trên một Node cụ thể sẽ trực tiếp quản lý nó.
kubeletsẽ theo dõi một thư mục trên máy chủ (ví dụ:/etc/kubernetes/manifests).- Bất kỳ file YAML định nghĩa Pod nào được đặt trong thư mục này sẽ được
kubelettự động tạo ra. kubeletcũng tạo một "mirror Pod" trên API Server để bạn có thể thấy nó khi chạykubectl get pods, nhưng bạn không thể xóa nó từkubectl. Để xóa Static Pod, bạn phải xóa file YAML khỏi thư-mục-manifest trên Node.
Tại sao lại cần Static Pods? Chúng chủ yếu được sử dụng để chạy các thành phần của chính Control Plane (như kube-apiserver, kube-scheduler, etcd) trong các cluster được cài đặt bằng công cụ kubeadm. Bằng cách này, cluster có thể "tự khởi động" mà không cần một Control Plane đã có sẵn từ trước.
Đối với developer, bạn gần như sẽ không bao giờ phải tạo hay quản lý Static Pods.
Kết luận Chương 4: Chúng ta đã tìm hiểu sâu về Pod - đơn vị cơ bản nhất của Kubernetes. Chúng ta đã hiểu tại sao Pod là một sự trừu tượng hóa mạnh mẽ hơn container, cách nó hoạt động qua các giai đoạn trong vòng đời, và cách định nghĩa nó bằng YAML. Quan trọng hơn, chúng ta đã khám phá các mẫu thiết kế mạnh mẽ như Sidecar và Init Containers, những công cụ thiết yếu trong hộp đồ nghề của một Cloud-Native Developer. Giờ đây, khi đã nắm vững "viên gạch" Pod, chúng ta đã sẵn sàng để tìm hiểu về các "thợ xây" - những Controllers sẽ giúp chúng ta xây dựng các ứng dụng phức tạp và bền bỉ trong chương tiếp theo.
Chương 5: Controllers - Quản Lý Vòng Đời Ứng Dụng
Chúng ta đã học rằng việc tạo trực tiếp các Pod riêng lẻ là một ý tưởng tồi. Pod rất "mỏng manh": chúng có thể chết khi Node gặp sự cố, và sẽ không tự động được tạo lại. Vậy làm thế nào để triển khai một ứng dụng có khả năng chịu lỗi, có thể co giãn và cập nhật một cách an toàn? Câu trả lời nằm ở Controllers.
Controllers là các vòng lặp điều khiển (control loops) cốt lõi của Kubernetes. Chúng theo dõi trạng thái của cluster và hành động để đưa trạng thái thực tế về với trạng thái mong muốn mà bạn đã định nghĩa. Mỗi controller chịu trách nhiệm quản lý một khía cạnh cụ thể của vòng đời ứng dụng. Trong chương này, chúng ta sẽ khám phá các loại controller quan trọng nhất đối với developer.
5.1. ReplicaSet: Đảm bảo số lượng Pod luôn ổn định
- Nhiệm vụ: Mục đích duy nhất của một
ReplicaSetlà đảm bảo rằng một số lượng Pod (replica) nhất định luôn chạy tại mọi thời điểm. - Cách hoạt động:
- Bạn định nghĩa một
ReplicaSet, trong đó chỉ định:replicas: Số lượng Pod mong muốn (ví dụ: 3).selector: Một bộ cáclabelđể xác định những Pod nào thuộc về ReplicaSet này (ví dụ:app: nginx).template: Một khuôn mẫu (template) để tạo ra các Pod mới khi cần. Template này chính là phầnspeccủa một Pod.
- ReplicaSet Controller sẽ liên tục đếm số lượng Pod có
labelkhớp vớiselector. - Nếu số lượng thực tế ít hơn
replicas, nó sẽ sử dụngtemplateđể tạo thêm Pod mới. - Nếu số lượng thực tế nhiều hơn
replicas, nó sẽ xóa bớt các Pod dư thừa.
- Bạn định nghĩa một
Ví dụ YAML:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: my-app-replicaset
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: my-app-container
image: nginxLưu ý quan trọng: Giống như Pod, bạn cũng gần như không bao giờ làm việc trực tiếp với
ReplicaSet.ReplicaSetđược coi là một khối xây dựng cấp thấp. Thay vào đó, chúng ta sử dụng một controller cấp cao hơn và mạnh mẽ hơn rất nhiều:Deployment.
5.2. Deployment: Trái tim của ứng dụng stateless
Deployment là đối tượng bạn sẽ sử dụng thường xuyên nhất để triển khai các ứng dụng stateless (ứng dụng không lưu trữ trạng thái, ví dụ: web server, API backend, v.v.).
Deployment cung cấp một cách khai báo để quản lý vòng đời của ứng dụng, bao gồm:
- Tạo và quản lý
ReplicaSet:Deploymentkhông trực tiếp quản lý Pod. Thay vào đó, nó quản lý cácReplicaSet. Khi bạn tạo mộtDeployment, nó sẽ tự động tạo mộtReplicaSettương ứng. - Cập nhật ứng dụng (Rolling Updates): Cho phép bạn cập nhật ứng dụng lên phiên bản mới mà không có thời gian chết (zero-downtime).
- Rollback: Dễ dàng quay lại phiên bản trước đó nếu phiên bản mới gặp lỗi.
5.2.1. Khai báo một Deployment
File YAML của một Deployment trông rất giống ReplicaSet, nhưng có thêm các tùy chọn về chiến lược cập nhật.
# my-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx
# template này định nghĩa các Pod sẽ được tạo
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.21 # Phiên bản ban đầu
ports:
- containerPort: 80Bạn có thể tạo nó bằng kubectl apply -f my-deployment.yaml. Kubernetes sẽ tạo ra:
- Một
Deployment. - Một
ReplicaSetđược quản lý bởiDeploymentđó. - Ba
Podđược quản lý bởiReplicaSetđó.
Bạn có thể kiểm tra bằng các lệnh: kubectl get deployment, kubectl get replicaset, kubectl get pod.
5.2.2. Chiến lược cập nhật (Update Strategy)
Đây là sức mạnh thực sự của Deployment. Khi bạn thay đổi spec.template của Deployment (ví dụ: đổi image thành nginx:1.22), Deployment sẽ bắt đầu quá trình cập nhật.
Deployment hỗ trợ hai chiến lược (spec.strategy.type):
1. RollingUpdate (Mặc định và được khuyến khích): Đây là chiến lược cập nhật từ từ, đảm bảo tính sẵn sàng cao.
Deploymentsẽ tạo mộtReplicaSetmới với template mới, nhưng ban đầureplicascủa nó là 0.- Nó sẽ từ từ tăng số lượng Pod của
ReplicaSetmới, đồng thời giảm số lượng Pod củaReplicaSetcũ. - Quá trình này đảm bảo rằng tại mọi thời điểm, luôn có một số lượng Pod nhất định đang chạy để phục vụ người dùng.
Bạn có thể tùy chỉnh hành vi của RollingUpdate với:
maxUnavailable: Số lượng Pod tối đa có thể không khả dụng trong quá trình cập nhật (có thể là số tuyệt đối hoặc phần trăm).maxSurge: Số lượng Pod tối đa có thể được tạo ra vượt quá sốreplicasmong muốn (có thể là số tuyệt đối hoặc phần trăm).
Ví dụ: Với replicas: 10, maxUnavailable: 2, maxSurge: 1: Khi cập nhật, Kubernetes sẽ đảm bảo có ít nhất 10 - 2 = 8 Pod cũ đang chạy. Nó có thể tạo thêm 1 Pod mới (tổng số Pod lúc này là 11), sau đó xóa một Pod cũ. Quá trình tiếp diễn cho đến khi tất cả 10 Pod đều là phiên bản mới.
2. Recreate: Chiến lược này đơn giản hơn nhưng gây ra downtime.
Deploymentsẽ xóa tất cả các Pod của phiên bản cũ trước.- Sau khi tất cả Pod cũ đã bị xóa, nó mới bắt đầu tạo các Pod của phiên bản mới.
- Chỉ nên sử dụng chiến lược này khi ứng dụng của bạn không hỗ trợ chạy đồng thời hai phiên bản.
5.2.3. Rollback về phiên bản trước
Nếu phiên bản mới của bạn có lỗi, việc quay lại thật dễ dàng. Deployment lưu giữ lịch sử các ReplicaSet cũ của nó.
# Xem lịch sử các lần cập nhật (revisions)
kubectl rollout history deployment/my-nginx-deployment
# Quay lại phiên bản trước đó
kubectl rollout undo deployment/my-nginx-deployment
# Quay lại một phiên bản cụ thể
kubectl rollout undo deployment/my-nginx-deployment --to-revision=25.2.4. revisionHistoryLimit
Mỗi khi bạn cập nhật một Deployment, nó sẽ tạo một ReplicaSet mới và giữ lại ReplicaSet cũ để có thể rollback. Theo thời gian, số lượng ReplicaSet cũ có thể trở nên rất lớn.
Trường spec.revisionHistoryLimit (mặc định là 10) cho phép bạn chỉ định số lượng ReplicaSet cũ cần giữ lại. Các ReplicaSet cũ hơn nữa sẽ tự động bị dọn dẹp.
5.3. StatefulSet: Dành cho ứng dụng có trạng thái
Trong khi Deployment là lựa chọn hoàn hảo cho các ứng dụng stateless, thế giới thực còn có các ứng dụng stateful (có trạng thái) như database (MySQL, PostgreSQL, MongoDB), message queue (Kafka, RabbitMQ), v.v.
Các ứng dụng này có những yêu cầu đặc biệt mà Deployment không đáp ứng được:
- Định danh mạng ổn định: Mỗi Pod cần có một tên DNS cố định, không thay đổi ngay cả khi nó được khởi động lại.
- Lưu trữ ổn định: Mỗi Pod cần có một không gian lưu trữ riêng và bền bỉ. Khi Pod được khởi động lại, nó phải được gắn lại đúng vào không gian lưu trữ cũ của nó.
- Triển khai và co giãn có thứ tự: Các Pod cần được tạo, cập nhật và xóa theo một thứ tự nghiêm ngặt (ví dụ: Pod 0, rồi đến Pod 1, rồi đến Pod 2).
StatefulSet là controller được thiết kế để giải quyết chính xác những vấn đề này.
5.3.1. Sự khác biệt chính với Deployment
| Tính năng | Deployment | StatefulSet |
|---|---|---|
| Định danh Pod | Ngẫu nhiên (<tên>-<hash>) | Ổn định, có thứ tự (<tên>-0, <tên>-1) |
| Lưu trữ | Chia sẻ chung (nếu có) | Riêng biệt, ổn định cho mỗi Pod |
| Scaling/Update | Song song, ngẫu nhiên | Tuần tự, có thứ tự |
| Headless Service | Không bắt buộc | Bắt buộc để có định danh mạng |
5.3.2. Định danh mạng ổn định (Stable Network ID)
StatefulSet yêu cầu một Service đặc biệt gọi là Headless Service (spec.clusterIP: None). Service này không thực hiện cân bằng tải, thay vào đó, nó tạo ra các bản ghi DNS cho mỗi Pod của StatefulSet.
Nếu StatefulSet tên là db và Service tên là db-svc, bạn sẽ có:
- Pod
db-0có DNS làdb-0.db-svc.default.svc.cluster.local. - Pod
db-1có DNS làdb-1.db-svc.default.svc.cluster.local.
Các tên DNS này là cố định. Ngay cả khi Pod db-0 chết và được tạo lại trên một Node khác với IP mới, tên DNS của nó vẫn là db-0.db-svc....
5.3.3. Lưu trữ ổn định (Stable Storage)
StatefulSet sử dụng một cơ chế gọi là volumeClaimTemplates. Đây là một khuôn mẫu để tự động tạo ra một PersistentVolumeClaim (PVC) riêng cho mỗi Pod.
- Pod
db-0sẽ được gắn với PVCdata-db-0. - Pod
db-1sẽ được gắn với PVCdata-db-1.
Khi một Pod được tạo lại, StatefulSet đảm bảo nó sẽ được gắn lại đúng vào PVC của nó, giúp dữ liệu không bị mất.
Ví dụ YAML cho StatefulSet:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx" # Tên của Headless Service
replicas: 3
selector:
matchLabels:
app: nginx
template:
# ... template của Pod ...
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "my-storage-class"
resources:
requests:
storage: 1Gi5.3.4. Cập nhật và scaling có thứ tự
- Scaling up: Khi bạn scale từ 3 lên 5 replica,
StatefulSetsẽ tạopod-3, chờ nóReady, sau đó mới tạopod-4. - Scaling down: Khi bạn scale từ 5 xuống 3,
StatefulSetsẽ xóapod-4, chờ nó kết thúc hoàn toàn, sau đó mới xóapod-3. - Rolling Update: Khi cập nhật,
StatefulSetsẽ cập nhật các Pod theo thứ tự ngược lại:pod-N-1, rồi đếnpod-N-2,... cho đếnpod-0.
Thứ tự này rất quan trọng cho các hệ thống phân tán như database cluster, nơi thứ tự khởi động và tắt có thể ảnh hưởng đến trạng thái của cluster.
5.4. DaemonSet
- Nhiệm vụ: Đảm bảo rằng một bản sao của một Pod được chạy trên tất cả (hoặc một tập hợp) các Node trong cluster.
- Cách hoạt động: Khi một Node mới được thêm vào cluster,
DaemonSetsẽ tự động tạo một Pod trên đó. Khi một Node bị xóa, Pod tương ứng cũng bị xóa. - Trường hợp sử dụng:
- Agent thu thập log: Chạy một agent như
FluentdhoặcLogstashtrên mỗi Node để thu thập log từ tất cả các Pod trên Node đó. - Agent giám sát (Monitoring): Chạy một agent như
Prometheus Node ExporterhoặcDatadog Agenttrên mỗi Node để thu thập metrics của Node. - Storage provider: Chạy các thành phần của hệ thống lưu trữ phân tán như
GlusterFShoặcCephtrên mỗi Node.
- Agent thu thập log: Chạy một agent như
5.5. Job và CronJob: Tác vụ chạy một lần và theo lịch trình
Không phải tất cả các ứng dụng đều là các dịch vụ chạy mãi mãi. Đôi khi bạn chỉ cần chạy một tác vụ, và khi nó hoàn thành thì thôi.
Job
- Nhiệm vụ: Tạo ra một hoặc nhiều Pod và đảm bảo rằng một số lượng nhất định trong số chúng kết thúc thành công.
- Cách hoạt động:
Jobsẽ tiếp tục tạo lại Pod nếu Pod trước đó thất bại, cho đến khi tác vụ hoàn thành (Pod kết thúc với exit code 0). - Trường hợp sử dụng:
- Chạy một batch job xử lý dữ liệu.
- Thực hiện một tác vụ backup.
- Chạy một chương trình migration database.
CronJob
- Nhiệm vụ: Tạo ra các
Jobtheo một lịch trình lặp lại (giống như crontab trong Linux). - Cách hoạt động: Bạn định nghĩa một
schedulebằng cú pháp cron (ví dụ:"0 5 * * *"để chạy vào 5 giờ sáng mỗi ngày).CronJobcontroller sẽ tạo ra mộtJobmới vào mỗi thời điểm được lập lịch. - Trường hợp sử dụng:
- Backup định kỳ.
- Gửi email báo cáo hàng ngày.
- Dọn dẹp dữ liệu cũ hàng tuần.
Kết luận Chương 5: Chúng ta đã đi từ việc quản lý các Pod "mong manh" đến việc sử dụng các Controller mạnh mẽ để tự động hóa hoàn toàn vòng đời ứng dụng. Deployment là công cụ hàng ngày của bạn cho các ứng dụng stateless. StatefulSet giải quyết các thách thức phức tạp của ứng dụng stateful. DaemonSet đảm bảo các agent hệ thống có mặt ở mọi nơi. Và Job/CronJob xử lý các tác vụ theo lô và theo lịch trình. Nắm vững các controller này là bạn đã nắm được chìa khóa để vận hành các ứng dụng đáng tin cậy và có khả năng mở rộng trên Kubernetes. Trong chương tiếp theo, chúng ta sẽ giải quyết một câu hỏi quan trọng: Làm thế nào để kết nối các Pod này với nhau và với thế giới bên ngoài?
Chương 6: Service & Ingress - Kết Nối Với Thế Giới Bên Ngoài
Chúng ta đã có thể chạy và quản lý vòng đời của ứng dụng bằng Deployment và các controller khác. Nhưng một câu hỏi lớn vẫn còn đó: Làm thế nào để các ứng dụng này nói chuyện với nhau? Và làm thế nào để người dùng từ bên ngoài có thể truy cập vào chúng?
Các Pod trong Kubernetes có một đặc tính "bay hơi" (ephemeral):
- Chúng có thể bị xóa và tạo lại bất cứ lúc nào (do lỗi, do cập nhật, do co giãn).
- Mỗi lần một Pod được tạo lại, nó sẽ có một địa chỉ IP mới.
Rõ ràng, chúng ta không thể dựa vào địa chỉ IP của Pod để kết nối. Việc quản lý một danh sách IP động, thay đổi liên tục sẽ là một cơn ác mộng. Đây chính là lúc Service và Ingress vào cuộc.
6.1. Vấn đề kết nối trong Kubernetes
Hãy tưởng tượng bạn có một kiến trúc microservices đơn giản: một frontend-deployment (3 Pods) cần gọi đến một backend-deployment (5 Pods).
frontendcần biết địa chỉ củabackend. Nhưngbackendcó tới 5 Pod, mỗi Pod một IP khác nhau.frontendnên gọi đến IP nào?- Nếu một trong 5 Pod
backendchết và được tạo lại với IP mới, làm saofrontendbiết được? - Nếu
backendđược scale lên 10 Pod, làm saofrontendbiết để phân phối tải (load balance) đến cả 10 Pod đó?
Chúng ta cần một lớp trừu tượng, một "địa chỉ ảo" ổn định cho một nhóm các Pod cung cấp cùng một chức năng. Địa chỉ ảo đó chính là Service.
6.2. Service: Trừu tượng hóa kết nối đến Pods
Một Service trong Kubernetes là một đối tượng API định nghĩa một cách logic để truy cập một tập hợp các Pod. Tập hợp các Pod này thường được xác định bởi một selector dựa trên label.
Khi bạn tạo một Service, nó sẽ được cấp một địa chỉ IP ảo, ổn định (gọi là Cluster IP) và một tên DNS. Địa chỉ IP và tên DNS này sẽ không thay đổi trong suốt vòng đời của Service.
- Service Discovery: Các Pod khác trong cluster có thể tìm thấy và kết nối đến
Servicenày thông qua tên DNS. - Load Balancing: Khi traffic được gửi đến địa chỉ IP của
Service,kube-proxytrên mỗi node sẽ tự động chặn traffic đó và phân phối nó đến một trong các Pod "khỏe mạnh" (healthy) ở phía sau.
Ví dụ YAML cho một Service:
# my-backend-service.yaml
apiVersion: v1
kind: Service
metadata:
name: backend-service
spec:
# Selector này phải khớp với label của các Pod backend
selector:
app: my-backend
ports:
- protocol: TCP
port: 80 # Port mà Service sẽ lắng nghe
targetPort: 8080 # Port mà container trong Pod đang lắng nghe
# type mặc định là ClusterIP
type: ClusterIPselector: Đây là phần quan trọng nhất.Servicesẽ liên tục tìm kiếm tất cả các Pod cólabelkhớp vớiselectornày (ví dụ:app: my-backend) và tự động cập nhật danh sách các endpoint của nó.ports: Định nghĩa cách ánh xạ port.port: Port mà các Pod khác sẽ sử dụng để gọi đếnServicenày.targetPort: Port thực tế mà container trong các Pod backend đang mở.
Kubernetes cung cấp 4 loại (type) Service khác nhau để đáp ứng các nhu cầu kết nối khác nhau.
6.2.1. ClusterIP (Mặc định)
- Chức năng: Phơi bày
Servicetrên một địa chỉ IP nội bộ trong cluster. - Đặc điểm:
Servicechỉ có thể được truy cập từ bên trong cluster.- Đây là loại
Servicephổ biến nhất, được sử dụng cho giao tiếp giữa các microservices (ví dụ: frontend gọi backend, backend gọi database).
- Cách hoạt động:
kube-proxytạo các quy tắciptables/IPVStrên mỗi node để chuyển tiếp traffic từClusterIP:portđếnPodIP:targetPortcủa một trong các Pod backend.
6.2.2. NodePort
- Chức năng: Phơi bày
Servicetrên một port tĩnh trên mỗi Worker Node trong cluster. - Đặc điểm:
- Kubernetes sẽ tự động chọn một port trong một dải mặc định (ví dụ: 30000-32767) và mở port đó trên tất cả các Node.
- Bất kỳ traffic nào gửi đến
NodeIP:NodePortsẽ được chuyển tiếp đếnService. ServiceloạiNodePortcũng tự động tạo ra mộtClusterIP.
- Trường hợp sử dụng:
- Khi bạn cần nhanh chóng phơi bày một ứng dụng ra bên ngoài để test hoặc demo mà không muốn thiết lập
LoadBalancerphức tạp. - Đây là một khối xây dựng cơ bản cho các đối tượng cấp cao hơn như
LoadBalancervàIngress.
- Khi bạn cần nhanh chóng phơi bày một ứng dụng ra bên ngoài để test hoặc demo mà không muốn thiết lập
- Nhược điểm:
- Bạn phải tự quản lý việc truy cập đến IP của Node.
- Chỉ có thể sử dụng một port cho một service.
- Không phải là cách tốt nhất để triển khai ứng dụng production ra ngoài internet.
6.2.3. LoadBalancer
- Chức năng: Tự động tạo ra một bộ cân bằng tải (Load Balancer) của nhà cung cấp đám mây (ví dụ: AWS Elastic Load Balancer, Google Cloud Load Balancer) và trỏ nó vào
Servicecủa bạn. - Đặc điểm:
- Đây là cách tiêu chuẩn và được khuyến khích nhất để phơi bày một ứng dụng ra internet một cách đáng tin cậy.
ServiceloạiLoadBalancercũng tự động tạo ra mộtNodePortvà mộtClusterIP. Load Balancer của cloud sẽ trỏ traffic đến cácNodePorttrên các Node của bạn.
- Trường hợp sử dụng: Phơi bày các ứng dụng (thường là các ứng dụng không phải HTTP/HTTPS hoặc cần kết nối TCP/UDP trực tiếp) ra internet.
- Lưu ý: Loại
Servicenày chỉ hoạt động trong môi trường cloud có hỗ trợ (AWS, GCP, Azure, v.v.) hoặc các môi trường on-premise có cài đặt các controller đặc biệt như MetalLB.
6.2.4. ExternalName
- Chức năng: Đây là một loại
Serviceđặc biệt, không cóselectorvà không trỏ đến Pod nào. Thay vào đó, nó hoạt động như một bí danh (alias) cho một tên DNS bên ngoài. - Cách hoạt động: Nó trả về một bản ghi
CNAMEtrong hệ thống DNS nội bộ của cluster. - Trường hợp sử dụng: Cho phép các ứng dụng bên trong cluster truy cập một dịch vụ bên ngoài (ví dụ: một database RDS của AWS, một API của bên thứ ba) bằng một tên nội bộ, thay vì phải hardcode tên DNS bên ngoài vào code.
6.3. Service Discovery: Kubernetes DNS
Vậy làm thế nào Pod frontend biết được ClusterIP của backend-service? Câu trả lời là DNS.
Kubernetes cluster đi kèm với một máy chủ DNS nội bộ (thường là CoreDNS). Máy chủ này sẽ tự động tạo ra các bản ghi DNS cho mỗi Service được tạo.
Một Service có tên my-svc trong namespace my-ns sẽ có một bản ghi DNS là my-svc.my-ns.svc.cluster.local.
- Các Pod trong cùng
namespacemy-nscó thể truy cập nó đơn giản bằng tênmy-svc. - Các Pod trong
namespacekhác có thể truy cập nó bằng tên đầy đủmy-svc.my-ns.
Đây là cơ chế Service Discovery mặc định và mạnh mẽ của Kubernetes. Developer chỉ cần quan tâm đến tên của Service, không cần quan tâm đến địa chỉ IP.
6.4. Ingress: Quản lý truy cập HTTP/HTTPS từ bên ngoài
Service loại LoadBalancer rất tốt, nhưng nó có một nhược điểm: mỗi Service cần một Load Balancer riêng, và Load Balancer trên cloud thì không hề rẻ. Nếu bạn có 20 microservice cần phơi bày ra ngoài, bạn sẽ cần 20 Load Balancer? Điều này rất tốn kém và khó quản lý.
Hơn nữa, Service hoạt động ở Layer 4 (TCP/UDP). Nó không hiểu gì về HTTP, không thể thực hiện routing dựa trên URL path hay hostname.
Ingress được sinh ra để giải quyết vấn đề này. Ingress là một đối tượng API quản lý truy cập từ bên ngoài vào các Service trong cluster, chủ yếu cho HTTP và HTTPS.
Ingress có thể cung cấp:
- Routing dựa trên Hostname:
foo.example.com->foo-service,bar.example.com->bar-service. - Routing dựa trên Path:
example.com/api->api-service,example.com/ui->ui-service. - Termination SSL/TLS: Giải mã các kết nối HTTPS tại Ingress và gửi traffic HTTP không mã hóa đến các Pod.
- Cân bằng tải Layer 7.
6.4.1. Ingress Controller là gì?
Bản thân đối tượng Ingress bạn tạo ra không làm gì cả. Nó chỉ là một tập hợp các quy tắc routing. Để các quy tắc này có hiệu lực, bạn cần một Ingress Controller.
Ingress Controller là một ứng dụng thực sự (thường là một Deployment chạy trong cluster) có nhiệm vụ:
- Theo dõi các đối tượng
Ingressđược tạo/sửa/xóa. - Đọc các quy tắc routing từ các đối tượng
Ingress. - Cấu hình một reverse proxy/load balancer (như Nginx, HAProxy, Traefik) theo các quy tắc đó.
- Nhận traffic từ bên ngoài (thường thông qua một
ServiceloạiLoadBalancerhoặcNodePort) và định tuyến nó đến cácServicenội bộ tương ứng.
Các Ingress Controller phổ biến:
- NGINX Ingress Controller (do cộng đồng Kubernetes duy trì)
- Traefik
- HAProxy Ingress
- Và nhiều loại khác từ các nhà cung cấp cloud.
6.4.2. Cấu hình Ingress cho routing
Hãy xem một ví dụ về file Ingress định tuyến traffic cho hai service khác nhau:
# my-ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: simple-fanout-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- host: my-app.example.com
http:
paths:
- path: /login
pathType: Prefix
backend:
service:
name: login-service
port:
number: 8080
- path: /orders
pathType: Prefix
backend:
service:
name: order-service
port:
number: 80File này định nghĩa các quy tắc sau:
- Tất cả traffic đến host
my-app.example.com. - Nếu path bắt đầu bằng
/login, chuyển đếnlogin-serviceở port8080. - Nếu path bắt đầu bằng
/orders, chuyển đếnorder-serviceở port80.
6.4.3. Cấu hình TLS/SSL
Ingress giúp việc quản lý TLS trở nên tập trung và dễ dàng. Thay vì phải cấu hình certificate cho từng ứng dụng, bạn chỉ cần cấu hình nó tại Ingress.
- Tạo một
Secretchứa TLS certificate và private key của bạn:bashkubectl create secret tls my-tls-secret --key /path/to/tls.key --cert /path/to/tls.crt - Tham chiếu đến
Secretđó trong fileIngress:yamlapiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: tls-ingress spec: tls: - hosts: - my-app.example.com secretName: my-tls-secret # Tên của Secret đã tạo rules: - host: my-app.example.com http: paths: - path: / pathType: Prefix backend: service: name: my-service port: number: 80
Ingress Controller sẽ tự động lấy certificate từ Secret và cấu hình reverse proxy để thực hiện TLS termination.
6.5. Gateway API: Tương lai của Ingress
Mặc dù Ingress rất mạnh mẽ, nó cũng có một số hạn chế:
- Thiết kế ban đầu quá đơn giản, dẫn đến việc phải dùng rất nhiều
annotationscho các tính năng nâng cao, mỗi Ingress Controller lại có một bộannotationsriêng. - Mô hình quyền hạn không rõ ràng. Developer có thể vô tình "chiếm" một path của team khác.
Gateway API là một tập hợp các tài nguyên API mới (đang được phát triển và dần trở thành tiêu chuẩn) nhằm giải quyết các vấn đề của Ingress. Nó có các đặc điểm nổi bật:
- Phân chia vai trò rõ ràng:
GatewayClass: Được định nghĩa bởi admin hạ tầng (ví dụ: "đây là Nginx Ingress Controller").Gateway: Được yêu cầu bởi admin cluster (ví dụ: "tôi muốn một load balancer ở cổng 443 cho team A").HTTPRoute: Được tạo bởi developer (ví dụ: "với gateway của team A, hãy route path/foođến service của tôi").
- Mở rộng và linh hoạt: API được thiết kế để có thể mở rộng một cách tự nhiên mà không cần
annotations. - Hỗ trợ nhiều giao thức hơn: Không chỉ HTTP/HTTPS mà còn TCP, UDP, gRPC.
Gateway API đang dần được các Ingress Controller lớn hỗ trợ và được coi là sự thay thế thế hệ tiếp theo cho Ingress.
Kết luận Chương 6: Chúng ta đã giải quyết được bài toán kết nối trong Kubernetes. Service cung cấp một địa chỉ IP và DNS ổn định, cùng khả năng cân bằng tải nội bộ cho các Pod "bay hơi". Ingress cung cấp một cổng vào thông minh (Layer 7) cho traffic HTTP/HTTPS từ thế giới bên ngoài, cho phép routing linh hoạt và quản lý TLS tập trung. Nắm vững hai khái niệm này là bạn đã có thể xây dựng và kết nối các hệ thống microservices hoàn chỉnh trên Kubernetes. Trong chương tiếp theo, chúng ta sẽ đối mặt với một thách thức khác: làm thế nào để quản lý cấu hình và các dữ liệu nhạy cảm một cách an toàn và hiệu quả?
Chương 7: ConfigMap & Secret - Quản Lý Cấu Hình
Một ứng dụng hiện đại không chỉ có code. Nó còn có rất nhiều thông số cấu hình: chuỗi kết nối database, địa chỉ các API khác, các cờ bật/tắt tính năng (feature flags), v.v. Quản lý các cấu hình này một cách hiệu quả và an toàn là một thách thức lớn, đặc biệt trong môi trường microservices năng động như Kubernetes.
7.1. Tách biệt cấu hình khỏi code
Một trong những nguyên tắc cốt lõi của "The Twelve-Factor App" (một bộ sưu tập các phương pháp hay nhất để xây dựng ứng dụng SaaS) là "Lưu trữ cấu hình trong môi trường" (Store config in the environment).
Điều này có nghĩa là chúng ta phải tách biệt hoàn toàn cấu hình khỏi mã nguồn ứng dụng. Việc "hardcode" cấu hình (ví dụ: viết thẳng chuỗi kết nối database vào code) là một thực hành cực kỳ tồi tệ vì những lý do sau:
- Thiếu linh hoạt: Mỗi khi bạn muốn thay đổi cấu hình (ví dụ: trỏ đến một database khác), bạn phải sửa code, build lại container image và triển khai lại từ đầu.
- Rủi ro bảo mật: Đưa các thông tin nhạy cảm như mật khẩu, API key vào code và đẩy lên Git là một thảm họa bảo mật đang chờ xảy ra.
- Khó quản lý: Cùng một container image không thể được sử dụng cho các môi trường khác nhau (dev, staging, production) vì cấu hình đã bị "đóng cứng" bên trong.
Kubernetes cung cấp hai đối tượng API chuyên dụng để giải quyết bài toán này: ConfigMap cho dữ liệu cấu hình không nhạy cảm và Secret cho dữ liệu nhạy cảm.
7.2. ConfigMap: Lưu trữ dữ liệu cấu hình không nhạy cảm
Một ConfigMap là một đối tượng API dùng để lưu trữ dữ liệu cấu hình dưới dạng các cặp key-value. Dữ liệu này có thể là các giá trị đơn lẻ hoặc nội dung của cả một file cấu hình (ví dụ: app.properties, settings.xml).
Hãy coi ConfigMap như một "bảng băm" (hash map) mà bạn có thể tạo và quản lý bên ngoài các Pod của mình. Sau đó, bạn có thể "tiêm" (inject) các dữ liệu này vào Pod khi nó chạy.
7.2.1. Tạo ConfigMap
Bạn có thể tạo ConfigMap bằng nhiều cách khác nhau với kubectl.
1. Từ các giá trị trực tiếp (--from-literal): Hữu ích cho các cặp key-value đơn giản.
kubectl create configmap app-config \
--from-literal=app.theme=dark \
--from-literal=app.greeting="Hello World"2. Từ một file (--from-file): Mỗi file sẽ trở thành một entry trong ConfigMap, với key là tên file và value là nội dung file.
# Giả sử bạn có file app.properties
# app.properties:
# db.host=localhost
# db.port=5432
kubectl create configmap db-config --from-file=app.properties3. Từ một thư mục (--from-file): Tạo ConfigMap từ tất cả các file trong một thư mục.
# Giả sử thư mục 'config-dir' có 2 file: config.json và settings.xml
kubectl create configmap app-config-dir --from-file=./config-dir4. Từ file YAML: Đây là cách khai báo và phù hợp để quản lý trong Git (GitOps).
# app-config.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: my-app-config
data:
# Dữ liệu dạng key-value
app.color: "blue"
app.items: "5"
# Dữ liệu dạng file
config.json: |
{
"retryCount": 3,
"logLevel": "info"
}Sau đó tạo bằng kubectl apply -f app-config.yaml.
7.2.2. Sử dụng ConfigMap trong Pod
Có hai cách chính để một Pod có thể sử dụng dữ liệu từ ConfigMap.
1. Dưới dạng biến môi trường (Environment Variables): Đây là cách phổ biến nhất. Bạn có thể tiêm các key từ ConfigMap vào Pod dưới dạng các biến môi trường.
apiVersion: v1
kind: Pod
metadata:
name: my-app-pod
spec:
containers:
- name: my-app
image: my-app-image
env:
# Tiêm một key cụ thể từ ConfigMap
- name: APP_COLOR
valueFrom:
configMapKeyRef:
name: my-app-config # Tên ConfigMap
key: app.color # Key cần lấy
envFrom:
# Tiêm tất cả các key-value từ ConfigMap thành biến môi trường
- configMapRef:
name: my-app-configTrong ví dụ trên, container my-app sẽ có các biến môi trường:
APP_COLORvới giá trịblue.app.colorvới giá trịblue.app.itemsvới giá trị5.config.jsonvới giá trị là chuỗi JSON.
2. Dưới dạng file trong một Volume: Cách này rất hữu ích khi ứng dụng của bạn cần đọc cấu hình từ file, hoặc khi bạn có các file cấu hình lớn. ConfigMap sẽ được "mount" vào Pod như một thư mục.
apiVersion: v1
kind: Pod
metadata:
name: my-app-pod
spec:
containers:
- name: my-app
image: my-app-image
volumeMounts:
- name: config-volume
mountPath: "/etc/config # Mount vào thư mục /etc/config
volumes:
- name: config-volume
configMap:
name: my-app-config # Tên ConfigMapVới cấu hình này, bên trong container my-app, bạn sẽ thấy một thư mục /etc/config chứa các file:
/etc/config/app.color(nội dung làblue)/etc/config/app.items(nội dung là5)/etc/config/config.json(nội dung là chuỗi JSON)
Cập nhật động: Một tính năng rất mạnh mẽ là khi bạn mount
ConfigMapdưới dạng Volume, nếuConfigMapđược cập nhật, các file trong Pod cũng sẽ được tự động cập nhật sau một khoảng thời gian ngắn. Tuy nhiên, ứng dụng của bạn cần có khả năng phát hiện sự thay đổi của file và tải lại cấu hình. Việc cập nhậtConfigMapkhông tự động khởi động lại Pod.
7.3. Secret: Quản lý dữ liệu nhạy cảm
Secret có thiết kế và cách hoạt động rất giống với ConfigMap. Nó cũng là một đối tượng lưu trữ dữ liệu key-value. Tuy nhiên, Secret được thiết kế riêng cho các dữ liệu nhạy cảm như:
- Mật khẩu
- OAuth tokens
- Khóa SSH
- API keys
- TLS certificates
Sự khác biệt chính giữa Secret và ConfigMap không nằm ở cách chúng hoạt động, mà ở ý định (intent) và cách Kubernetes đối xử với chúng:
- Kubernetes sẽ cố gắng không ghi log nội dung của
Secret. - Kubernetes sẽ không hiển thị nội dung
Secrettrong các lệnh nhưkubectl describe(trừ khi bạn dùng cờ đặc biệt). - Dữ liệu
Secretđược lưu trữ trongetcdở dạng mã hóa (encryption at rest) nếu được cấu hình đúng. Secretcó thể được mount vào Pod dưới dạng file trong một volumetmpfs(lưu trên RAM thay vì disk) để tăng cường bảo mật.
7.3.1. Các loại Secret
Kubernetes có một số loại Secret tích hợp sẵn để phục vụ các mục đích cụ thể, ví dụ:
Opaque: Loại mặc định, dùng cho dữ liệu key-value bất kỳ.kubernetes.io/service-account-token: Dùng để lưu token choServiceAccount.kubernetes.io/dockerconfigjson: Dùng để lưu thông tin xác thực với một private container registry.kubernetes.io/tls: Dùng để lưu trữ TLS certificate và private key, thường được sử dụng bởiIngress.
7.3.2. Mã hóa Base64 và những lầm tưởng về bảo mật
Khi bạn tạo hoặc xem một Secret bằng kubectl, bạn sẽ thấy các giá trị của nó được mã hóa bằng Base64.
apiVersion: v1
kind: Secret
metadata:
name: my-secret
type: Opaque
data:
# "admin" được mã hóa base64
username: YWRtaW4=
# "supersecret" được mã hóa base64
password: c3VwZXJzZWNyZXQ=CẢNH BÁO QUAN TRỌNG: Base64 không phải là mã hóa (encryption). Nó chỉ là một phương pháp mã hóa dữ liệu nhị phân (binary encoding) để đảm bảo dữ liệu có thể được truyền đi an toàn dưới dạng văn bản. Bất kỳ ai cũng có thể giải mã một chuỗi Base64 một cách dễ dàng:
echo "YWRtaW4=" | base64 --decode
# Output: adminViệc mã hóa Base64 chỉ nhằm mục đích "che giấu" dữ liệu khỏi việc vô tình bị đọc lướt qua. Bảo mật thực sự của Secret đến từ cơ chế RBAC (ai có quyền đọc Secret) và việc cấu hình mã hóa khi lưu trữ (encryption at rest) trong etcd.
7.3.3. Sử dụng Secret trong Pod
Cách sử dụng Secret trong Pod hoàn toàn tương tự như ConfigMap.
1. Dưới dạng biến môi trường:
apiVersion: v1
kind: Pod
metadata:
name: my-app-pod
spec:
containers:
- name: my-app
image: my-app-image
env:
- name: DB_USERNAME
valueFrom:
secretKeyRef:
name: my-secret # Tên Secret
key: username # Key cần lấy
- name: DB_PASSWORD
valueFrom:
secretKeyRef:
name: my-secret
key: password2. Dưới dạng file trong một Volume: Đây là cách được khuyến khích hơn cho dữ liệu nhạy cảm, vì nó tránh phơi bày secret trong các biến môi trường (vốn có thể bị lộ qua log hoặc crash dump).
apiVersion: v1
kind: Pod
metadata:
name: my-app-pod
spec:
containers:
- name: my-app
image: my-app-image
volumeMounts:
- name: secret-volume
mountPath: "/etc/secrets"
readOnly: true # Luôn mount secret ở chế độ read-only
volumes:
- name: secret-volume
secret:
secretName: my-secret # Tên SecretBên trong container, ứng dụng của bạn có thể đọc username từ file /etc/secrets/username và password từ file /etc/secrets/password.
7.3.4. Các giải pháp quản lý Secret nâng cao
Mặc dù Secret của Kubernetes là một cải tiến lớn so với việc hardcode, nó vẫn có những hạn chế trong môi trường production yêu cầu bảo mật cao:
- Dữ liệu
Secretvẫn được lưu trongetcddưới dạng base64 (trừ khi đã cấu hình encryption at rest). - Việc quản lý vòng đời của secret (xoay vòng, thu hồi) vẫn còn thủ công.
- Developer vẫn có thể cần quyền truy cập trực tiếp vào
Secretđể debug.
Để giải quyết những vấn đề này, cộng đồng đã phát triển các giải pháp quản lý secret chuyên dụng, tích hợp với Kubernetes:
- HashiCorp Vault: Tiêu chuẩn vàng trong quản lý secret. Vault cung cấp các tính năng như mã hóa mạnh, cấp phát secret động, xoay vòng tự động, và audit log chi tiết. Nó tích hợp với Kubernetes thông qua một "sidecar injector", cho phép Pods lấy secret trực tiếp từ Vault một cách an toàn mà không cần lưu chúng trong
etcd. - Sealed Secrets: Một giải pháp GitOps-friendly. Nó cho phép bạn mã hóa
Secretcủa mình thành mộtSealedSecret(một CRD mới).SealedSecretnày an toàn để lưu trữ trong Git repository công khai. Một controller chạy trong cluster (và chỉ có controller này có private key) sẽ giải mãSealedSecretvà tạo raSecretthông thường. - Các dịch vụ quản lý secret của Cloud: AWS Secrets Manager, Google Secret Manager, Azure Key Vault.
Kết luận Chương 7:ConfigMap và Secret là hai công cụ thiết yếu để tách biệt cấu hình và dữ liệu nhạy cảm khỏi ứng dụng của bạn, giúp ứng dụng trở nên linh hoạt, di động và an toàn hơn. ConfigMap dành cho dữ liệu thông thường, trong khi Secret dành cho mật khẩu và API key, với các cơ chế bảo vệ bổ sung. Nắm vững cách tạo và sử dụng chúng là một kỹ năng cơ bản của mọi Kubernetes developer. Tuy nhiên, đối với dữ liệu, cấu hình chỉ là một phần của câu chuyện. Phần còn lại, và cũng là phần phức tạp hơn, là làm thế nào để lưu trữ dữ liệu bền bỉ cho các ứng dụng stateful. Chúng ta sẽ khám phá điều đó trong chương tiếp theo.
Chương 8: Storage - Lưu Trữ Dữ Liệu Bền Bỉ
Chúng ta đã học cách chạy các ứng dụng stateless với Deployment và các ứng dụng stateful với StatefulSet. Chúng ta cũng đã biết cách quản lý cấu hình với ConfigMap và Secret. Nhưng có một mảnh ghép quan trọng còn thiếu: dữ liệu.
Nếu một Pod database khởi động lại, làm thế nào để nó giữ lại được dữ liệu đã ghi trước đó? Nếu một Pod xử lý ảnh chết giữa chừng, làm thế nào để Pod thay thế có thể tiếp tục công việc từ đúng vị trí đó? Câu trả lời nằm ở hệ thống lưu trữ của Kubernetes.
8.1. Vấn đề lưu trữ trong môi trường container
Hệ thống file của một container có một đặc tính cố hữu: nó là éphémère (ephemeral - tạm thời). Khi một container bị xóa hoặc khởi động lại, tất cả các thay đổi được ghi vào hệ thống file của nó sẽ biến mất vĩnh viễn. Điều này là do thiết kế, giúp container luôn khởi động từ một trạng thái sạch sẽ và nhất quán.
Tuy nhiên, đối với hầu hết các ứng dụng trong thế giới thực, việc mất dữ liệu khi khởi động lại là không thể chấp nhận được. Chúng ta cần một cách để lưu trữ dữ liệu một cách bền bỉ (persistent), độc lập với vòng đời của Pod và Node.
Kubernetes giải quyết vấn đề này thông qua một hệ thống trừu tượng hóa lưu trữ mạnh mẽ, bao gồm ba khái niệm cốt lõi: Volume, PersistentVolume (PV), và PersistentVolumeClaim (PVC).
8.2. Volume: Vòng đời và các loại Volume
Khái niệm cơ bản nhất là Volume. Một Volume trong Kubernetes đơn giản là một thư mục chứa dữ liệu, được gắn (mount) vào một hoặc nhiều container trong một Pod.
Điểm mấu chốt là vòng đời của Volume được gắn với vòng đời của Pod, chứ không phải Container.
- Nếu một container trong Pod khởi động lại,
Volumevẫn còn đó, và container mới sẽ được mount vào đúngVolumeđó, giúp dữ liệu không bị mất. - Tuy nhiên, nếu chính
Podbị xóa và tạo lại,Volume(phụ thuộc vào loại) cũng có thể bị xóa.
Kubernetes hỗ trợ rất nhiều loại Volume, mỗi loại phục vụ một mục đích khác nhau. Dưới đây là một vài loại quan trọng đối với developer:
emptyDir:- Chức năng: Tạo ra một thư mục trống khi Pod được tạo.
- Vòng đời: Tồn tại chừng nào Pod còn tồn tại trên Node. Khi Pod bị xóa, dữ liệu trong
emptyDircũng bị xóa vĩnh viễn. - Trường hợp sử dụng:
- Làm không gian tạm (scratch space) cho các tác vụ tính toán.
- Chia sẻ file giữa các container trong cùng một Pod.
hostPath:- Chức năng: Mount một file hoặc thư mục từ hệ thống file của Node chủ (host machine) vào Pod.
- Vòng đời: Dữ liệu tồn tại trên Node ngay cả khi Pod bị xóa.
- CẢNH BÁO: Sử dụng
hostPathrất nguy hiểm và thường không được khuyến khích. Nó phá vỡ tính trừu tượng của Kubernetes, gắn chặt Pod vào một Node cụ thể, và có thể gây ra các vấn đề bảo mật nghiêm trọng (ví dụ: một Pod có thể truy cập vào các file hệ thống nhạy cảm của Node). Chỉ sử dụng khi bạn biết rõ mình đang làm gì (ví dụ: cho các agent hệ thống nhưDaemonSet).
configMapvàsecret:- Như chúng ta đã học ở chương trước, hai loại volume này được dùng để đưa dữ liệu từ các đối tượng
ConfigMapvàSecretvào Pod dưới dạng file.
- Như chúng ta đã học ở chương trước, hai loại volume này được dùng để đưa dữ liệu từ các đối tượng
Các loại volume trên vẫn chưa giải quyết được bài toán cốt lõi: làm thế nào để lưu trữ dữ liệu một cách bền bỉ, độc lập hoàn toàn với vòng đời của Pod và Node? Đây là lúc chúng ta cần đến PersistentVolume và PersistentVolumeClaim.
8.3. PersistentVolume (PV) và PersistentVolumeClaim (PVC): Trừu tượng hóa lưu trữ
Kubernetes đưa ra một mô hình trừu tượng hóa tuyệt vời để tách biệt việc quản lý hạ tầng lưu trữ (công việc của Admin) và việc sử dụng không gian lưu trữ (công việc của Developer).
PersistentVolume (PV):
- Là gì: Một "mẩu" không gian lưu trữ trong cluster đã được cung cấp (provisioned) bởi một quản trị viên (Admin).
- Vai trò: Đại diện cho một tài nguyên lưu trữ thực tế, ví dụ như một ổ đĩa GCE Persistent Disk, một volume AWS EBS, một thư mục NFS, hoặc một LUN của iSCSI.
- Đặc điểm: PV là một tài nguyên của cluster, giống như CPU hay RAM. Nó không thuộc về bất kỳ
namespacenào. Nó có vòng đời độc lập với bất kỳ Pod nào sử dụng nó.
PersistentVolumeClaim (PVC):
- Là gì: Một yêu cầu (request) cho không gian lưu trữ được đưa ra bởi một người dùng/developer.
- Vai trò: Giống như một Pod yêu cầu CPU và Memory, một PVC yêu cầu các thuộc tính lưu trữ cụ thể, như dung lượng (ví dụ: 5GB), và chế độ truy cập (ví dụ: chỉ cho phép một Pod ghi cùng lúc).
- Đặc điểm: PVC là một tài nguyên thuộc về một
namespacecụ thể. Developer tạo ra PVC mà không cần biết chi tiết về hạ tầng lưu trữ bên dưới.
Quá trình "Binding":
- Admin tạo ra một hoặc nhiều PV sẵn sàng trong cluster.
- Developer tạo một PVC để yêu cầu không gian lưu trữ cho ứng dụng của mình.
- Control Plane của Kubernetes sẽ tìm một PV phù hợp có thể đáp ứng yêu cầu của PVC đó (dựa trên dung lượng, access mode, v.v.).
- Nếu tìm thấy, Kubernetes sẽ "gắn" (bind) PV đó vào PVC. Lúc này, PVC được coi là đã được đáp ứng, và PV đó được dành riêng cho PVC này.
- Developer tạo một Pod và khai báo rằng Pod đó sử dụng PVC này.
- Kubernetes sẽ đảm bảo rằng Pod được lập lịch trên một Node có thể truy cập được vào tài nguyên lưu trữ vật lý mà PV đại diện, sau đó mount nó vào Pod.
Mô hình này rất mạnh mẽ vì nó tách biệt hoàn toàn hai vai trò:
- Admin: Chỉ cần tập trung vào việc cung cấp các loại hình lưu trữ khác nhau (PVs) cho cluster.
- Developer: Chỉ cần yêu cầu thứ mình cần (PVC) mà không cần quan tâm nó đến từ AWS, Google Cloud hay một hệ thống SAN on-premise.
Ví dụ:
# 1. PersistentVolume (do Admin tạo)
apiVersion: v1
kind: PersistentVolume
metadata:
name: my-pv
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
hostPath: # Sử dụng hostPath chỉ để demo, thực tế sẽ là gcePersistentDisk, awsElasticBlockStore, etc.
path: "/mnt/data"
---
# 2. PersistentVolumeClaim (do Developer tạo)
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-pvc
namespace: my-app-ns
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi # Yêu cầu 5GB
---
# 3. Pod (do Developer tạo, sử dụng PVC)
apiVersion: v1
kind: Pod
metadata:
name: my-storage-pod
namespace: my-app-ns
spec:
containers:
- name: my-container
image: nginx
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: my-storage
volumes:
- name: my-storage
persistentVolumeClaim:
claimName: my-pvc # Tham chiếu đến PVC đã tạo8.4. StorageClass: Cấp phát Volume động (Dynamic Provisioning)
Mô hình PV/PVC ở trên được gọi là cấp phát tĩnh (static provisioning): Admin phải tạo trước các PV. Điều này có thể ổn với một vài PV, nhưng sẽ trở nên cồng kềnh khi có hàng trăm developer cùng yêu cầu lưu trữ.
StorageClass ra đời để giải quyết vấn đề này thông qua cấp phát động (dynamic provisioning).
- Là gì: Một
StorageClassmô tả một "loại" lưu trữ mà bạn cung cấp. Ví dụ:fast-ssd,slow-hdd,backup-storage. MỗiStorageClasssẽ có mộtprovisioner(trình cấp phát) chỉ định plugin nào sẽ được sử dụng để tạo PV. - Cách hoạt động:
- Admin định nghĩa một hoặc nhiều
StorageClass(ví dụ: mộtStorageClasscho AWS EBS, một cho NFS). - Developer khi tạo PVC, thay vì để trống, sẽ chỉ định
storageClassNamemà họ muốn sử dụng. - Khi PVC được tạo, Kubernetes sẽ không đi tìm một PV có sẵn. Thay vào đó, nó sẽ ra lệnh cho
provisionercủaStorageClassđó tự động tạo ra một PV mới vừa khít với yêu cầu của PVC. - PV mới này sau đó sẽ được bind với PVC.
- Admin định nghĩa một hoặc nhiều
Ví dụ về StorageClass và PVC sử dụng nó:
# 1. StorageClass (do Admin tạo)
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: standard-ssd
provisioner: kubernetes.io/gce-pd # Sử dụng provisioner của Google Persistent Disk
parameters:
type: pd-standard # Loại disk là standard
fstype: ext4
replication-type: none
---
# 2. PersistentVolumeClaim (do Developer tạo)
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-dynamic-pvc
namespace: my-app-ns
spec:
storageClassName: "standard-ssd" # Yêu cầu storage từ class này
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20GiKhi PVC my-dynamic-pvc được tạo, StorageClass standard-ssd sẽ tự động gọi API của Google Cloud để tạo ra một ổ đĩa pd-standard 20GB, sau đó tạo một PV tương ứng và bind nó vào PVC. Quá trình này hoàn toàn tự động.
8.5. Access Modes: Chế độ truy cập
Khi yêu cầu lưu trữ, bạn cần chỉ định cách mà bạn muốn các Pod truy cập vào Volume. Có 3 chế độ truy cập chính:
ReadWriteOnce(RWO):- Volume có thể được mount để đọc-ghi bởi một Node duy nhất tại một thời điểm.
- Nhiều Pod trên cùng một Node có thể mount vào Volume này.
- Đây là access mode phổ biến nhất và được hỗ trợ bởi hầu hết các loại volume.
ReadOnlyMany(ROX):- Volume có thể được mount để chỉ đọc bởi nhiều Node cùng một lúc.
ReadWriteMany(RWX):- Volume có thể được mount để đọc-ghi bởi nhiều Node cùng một lúc.
- Chế độ này phức tạp hơn và chỉ được hỗ trợ bởi các hệ thống lưu trữ có khả năng chia sẻ file như NFS, GlusterFS, CephFS.
Việc lựa chọn access mode phụ thuộc vào ứng dụng của bạn và khả năng của hệ thống lưu trữ bên dưới.
8.6. Các giải pháp lưu trữ cho Kubernetes
Hệ sinh thái lưu trữ cho Kubernetes rất rộng lớn. Các giải pháp thường được chia thành các loại sau:
- Cloud Provider Storage: Tích hợp chặt chẽ nhất. Mỗi cloud có các plugin (CSI - Container Storage Interface) riêng:
- AWS:
aws-ebs-csi-driver - Google Cloud:
pd-csi-driver - Azure:
azure-disk-csi-driver,azure-file-csi-driver
- AWS:
- Hệ thống lưu trữ phân tán (Distributed Storage): Các giải pháp phần mềm có thể chạy cả bên trong và bên ngoài Kubernetes, cung cấp các tính năng nâng cao như
ReadWriteMany, snapshot, replication.- Ceph (qua Rook): Một giải pháp mã nguồn mở cực kỳ mạnh mẽ và phổ biến, cung cấp cả block, file và object storage.
- GlusterFS: Một hệ thống file phân tán mã nguồn mở khác.
- Longhorn: Một giải pháp lưu trữ block phân tán dễ sử dụng, là dự án của CNCF.
- Hệ thống lưu trữ truyền thống:
- NFS (Network File System): Một cách đơn giản để có được
ReadWriteMany, nhưng có thể có vấn đề về hiệu năng và single-point-of-failure. - iSCSI, Fibre Channel: Các giao thức lưu trữ block-level từ các hệ thống SAN.
- NFS (Network File System): Một cách đơn giản để có được
Kết luận Chương 8: Lưu trữ bền bỉ là một trong những khía cạnh phức tạp nhưng quan trọng nhất của Kubernetes. Bằng cách trừu tượng hóa lưu trữ qua các khái niệm Volume, PersistentVolume (PV), PersistentVolumeClaim (PVC), và StorageClass, Kubernetes đã tạo ra một mô hình linh hoạt, cho phép developer yêu cầu tài nguyên lưu trữ một cách dễ dàng trong khi vẫn cho phép admin toàn quyền kiểm soát hạ tầng bên dưới. Hiểu rõ cách các thành phần này tương tác với nhau là chìa khóa để xây dựng các ứng dụng stateful đáng tin cậy trên Kubernetes. Trong phần tiếp theo, chúng ta sẽ chuyển sang các chủ đề về vận hành, bắt đầu với việc làm thế nào để đảm bảo các ứng dụng của chúng ta luôn "khỏe mạnh" và sử dụng tài nguyên một cách hiệu quả.
Phần III: Vận Hành và Tối Ưu Hóa cho Developer
Chương 9: Health Checks và Quản Lý Tài Nguyên
Việc triển khai được một ứng dụng chỉ là bước khởi đầu. Để vận hành một hệ thống đáng tin cậy, chúng ta cần trả lời hai câu hỏi quan trọng:
- Làm sao để biết ứng dụng của chúng ta vẫn đang hoạt động bình thường và sẵn sàng phục vụ người dùng?
- Làm sao để đảm bảo ứng dụng có đủ tài nguyên (CPU, Memory) để chạy, nhưng cũng không chiếm dụng quá mức gây ảnh hưởng đến các ứng dụng khác?
Chương này sẽ đi sâu vào hai cơ chế cốt lõi của Kubernetes giúp giải quyết những vấn đề trên: Health Checks (Probes) và Resource Management (Requests & Limits).
9.1. Liveness Probe: Pod của bạn có còn "sống"?
Vấn đề: Đôi khi, một ứng dụng vẫn đang chạy (tiến trình process vẫn tồn tại) nhưng lại rơi vào trạng thái không thể hoạt động được, ví dụ như bị deadlock, hết bộ nhớ, hoặc một vòng lặp vô hạn. Từ bên ngoài, tiến trình vẫn "sống", nhưng nó không còn khả năng xử lý yêu cầu hay làm bất cứ việc gì hữu ích.
Giải pháp: Liveness Probe (Thăm dò sự sống) là một cơ chế cho phép kubelet kiểm tra xem một container có còn hoạt động đúng cách hay không.
- Nếu Liveness Probe thành công:
kubeletkhông làm gì cả. - Nếu Liveness Probe thất bại:
kubeletsẽ giết (kill) container đó và khởi động lại nó theorestartPolicycủa Pod.
Hành động "giết và khởi động lại" này cực kỳ hiệu quả trong việc tự động phục hồi các ứng dụng bị treo.
Kubernetes cung cấp ba cách để thực hiện một probe:
- HTTP Probe (
httpGet):kubeletgửi một yêu cầu HTTP GET đến một endpoint cụ thể trong container của bạn. Nếu nhận được mã trả về trong khoảng 200-399, probe được coi là thành công. - TCP Probe (
tcpSocket):kubeletcố gắng mở một kết nối TCP đến một port cụ thể trong container. Nếu kết nối thành công, probe được coi là thành công. - Command Probe (
exec):kubeletthực thi một lệnh bên trong container. Nếu lệnh trả về exit code 0, probe được coi là thành công.
Ví dụ về Liveness Probe:
apiVersion: v1
kind: Pod
metadata:
name: liveness-pod
spec:
containers:
- name: my-app
image: my-app-image
livenessProbe:
httpGet:
path: /healthz # Endpoint kiểm tra sức khỏe
port: 8080
initialDelaySeconds: 15 # Chờ 15 giây sau khi container khởi động mới bắt đầu probe
periodSeconds: 20 # Thực hiện probe mỗi 20 giây
timeoutSeconds: 1 # Coi là thất bại nếu không nhận được phản hồi sau 1 giây
failureThreshold: 3 # Coi là thất bại thực sự sau 3 lần probe liên tiếp thất bại9.2. Readiness Probe: Pod đã sẵn sàng nhận request chưa?
Vấn đề: Một ứng dụng có thể đã khởi động (liveness probe thành công) nhưng chưa sẵn sàng để nhận traffic. Ví dụ:
- Một ứng dụng Java cần thời gian để khởi tạo Spring context, nạp dữ liệu vào cache.
- Một ứng dụng cần kết nối đến database và thực hiện các migration ban đầu.
Nếu Service gửi traffic đến Pod ngay khi nó vừa khởi động, người dùng có thể sẽ gặp lỗi.
Giải pháp: Readiness Probe (Thăm dò sự sẵn sàng) được dùng để cho Kubernetes biết khi nào một container đã sẵn sàng để bắt đầu nhận traffic.
- Nếu Readiness Probe thành công:
kubeletsẽ đánh dấu Pod làReady.Servicesẽ bắt đầu đưa Pod này vào danh sách các endpoint hợp lệ và gửi traffic đến nó. - Nếu Readiness Probe thất bại:
kubeletsẽ đánh dấu Pod làNotReady.Servicesẽ xóa Pod này khỏi danh sách endpoint. Traffic sẽ không được gửi đến nó nữa cho đến khi probe thành công trở lại.
Quan trọng là, nếu Readiness Probe thất bại, kubelet sẽ không khởi động lại container. Nó chỉ tạm thời "cách ly" Pod ra khỏi luồng traffic.
Tại sao Readiness Probe lại quan trọng cho Rolling Update? Khi bạn thực hiện một Deployment rolling update, Kubernetes sẽ chỉ coi một Pod mới là "sẵn sàng" khi Readiness Probe của nó thành công. Điều này đảm bảo rằng Pod mới chỉ nhận traffic khi nó đã thực sự sẵn sàng 100%, giúp quá trình cập nhật diễn ra mượt mà không gây lỗi cho người dùng (zero-downtime deployment).
Ví dụ về Readiness Probe: Cấu hình của Readiness Probe hoàn toàn tương tự Liveness Probe.
apiVersion: v1
kind: Pod
metadata:
name: readiness-pod
spec:
containers:
- name: my-app
image: my-app-image
readinessProbe:
httpGet:
path: /ready
port: 8080
initialDelaySeconds: 5
periodSeconds: 10Best Practice: Luôn luôn định nghĩa cả
LivenessvàReadinessprobe.Livenessđể khởi động lại ứng dụng bị treo,Readinessđể đảm bảo cập nhật an toàn và không gửi traffic đến ứng dụng chưa sẵn sàng. Endpoint củaReadinessprobe thường phức tạp hơn, có thể cần kiểm tra cả kết nối đến database, message queue, v.v.
9.3. Startup Probe: Dành cho các ứng dụng khởi động chậm
Vấn đề: Một số ứng dụng (đặc biệt là các ứng dụng Java cũ hoặc các ứng dụng cần thực hiện nhiều tác vụ nặng khi khởi động) có thể mất vài phút để bắt đầu. Nếu initialDelaySeconds của Liveness Probe quá ngắn, kubelet có thể giết chết container trước khi nó kịp khởi động xong, gây ra một vòng lặp khởi động lại không hồi kết (CrashLoopBackOff).
Giải pháp: Startup Probe (Thăm dò khởi động) được thiết kế đặc biệt cho trường hợp này.
- Khi
Startup Probeđược định nghĩa, tất cả các probe khác sẽ bị vô hiệu hóa cho đến khiStartup Probethành công. Startup Probecó một khoảng thời gian dài (failureThreshold*periodSeconds) để hoàn thành.- Nếu Startup Probe thành công:
kubeletsẽ bắt đầu thực hiệnLivenessvàReadinessprobe như bình thường. - Nếu Startup Probe thất bại (vượt quá thời gian cho phép):
kubeletsẽ giết và khởi động lại container.
Ví dụ về Startup Probe:
startupProbe:
httpGet:
path: /healthz
port: 8080
failureThreshold: 30 # Thử lại 30 lần
periodSeconds: 10 # Mỗi lần cách nhau 10 giây
# => Container có tổng cộng 30 * 10 = 300 giây (5 phút) để khởi động.9.4. Requests và Limits: Quản lý CPU và Memory
Trong một cluster chia sẻ, việc quản lý tài nguyên là tối quan trọng. Kubernetes cho phép bạn chỉ định lượng CPU và Memory mà mỗi container cần và được phép sử dụng thông qua hai tham số: requests và limits.
requests (Yêu cầu):
- Ý nghĩa: Lượng tài nguyên được đảm bảo (guaranteed) cho container.
- Cách hoạt động:
- Memory Request: Kubernetes đảm bảo container sẽ luôn có ít nhất lượng memory này.
- CPU Request: Kubernetes đảm bảo container sẽ nhận được phần CPU tương ứng. CPU là tài nguyên có thể "nén" được (compressible), nên nếu có CPU nhàn rỗi, container có thể dùng nhiều hơn mức request.
- Vai trò với Scheduler:
kube-schedulersử dụngrequestsđể quyết định đặt Pod ở đâu. Nó sẽ chỉ đặt Pod lên một Node nếu Node đó có đủ tài nguyên chưa được cấp phát để đáp ứngrequestscủa Pod.
limits (Giới hạn):
- Ý nghĩa: Lượng tài nguyên tối đa mà container được phép sử dụng.
- Cách hoạt động:
- Memory Limit: Nếu container cố gắng sử dụng nhiều memory hơn
limit, nó sẽ bị giết với lỗi OOMKilled (Out of Memory). - CPU Limit: Nếu container cố gắng sử dụng nhiều CPU hơn
limit, nó sẽ bị điều tiết (throttled), tức là hiệu năng sẽ bị giảm xuống để không vượt quá giới hạn. Container sẽ không bị giết.
- Memory Limit: Nếu container cố gắng sử dụng nhiều memory hơn
Đơn vị đo lường:
- Memory:
Ki(Kibibyte),Mi(Mebibyte),Gi(Gibibyte),Ti(Tebibyte). - CPU:
m(millicpu hoặc millicore).1000mtương đương với 1 vCPU/core.500mlà nửa core.
Ví dụ:
resources:
requests:
memory: "64Mi"
cpu: "250m" # 0.25 core
limits:
memory: "128Mi"
cpu: "500m" # 0.5 coreBest Practice: Luôn luôn đặt
requestsvàlimitscho mọi container trong môi trường production. Điều này giúp Scheduler đưa ra quyết định tốt hơn, tránh tình trạng "hàng xóm ồn ào" (một Pod dùng quá nhiều tài nguyên ảnh hưởng đến các Pod khác), và làm cho cluster hoạt động ổn định hơn.
9.5. Quality of Service (QoS) Classes
Dựa trên cách bạn đặt requests và limits, Kubernetes sẽ tự động gán cho Pod của bạn một trong ba lớp Chất lượng Dịch vụ (QoS). Lớp QoS này quyết định Pod nào sẽ bị giết trước tiên khi Node cạn kiệt tài nguyên (đặc biệt là Memory).
Guaranteed(Đảm bảo):- Điều kiện: Mọi container trong Pod phải có cả
memory requestvàmemory limit, và chúng phải bằng nhau. Tương tự cho CPU. - Đặc điểm: Đây là các Pod có độ ưu tiên cao nhất. Chúng sẽ là những Pod cuối cùng bị giết nếu Node hết tài nguyên.
- Ví dụ:yaml
resources: requests: memory: "128Mi" cpu: "500m" limits: memory: "128Mi" cpu: "500m"
- Điều kiện: Mọi container trong Pod phải có cả
Burstable(Có thể bùng nổ):- Điều kiện: Ít nhất một container trong Pod có
requestnhưnglimitlớn hơnrequest, hoặc chỉ córequestmà không cólimit. - Đặc điểm: Các Pod này được phép "bùng nổ" sử dụng nhiều tài nguyên hơn mức request nếu có tài nguyên nhàn rỗi trên Node. Chúng có độ ưu tiên trung bình và sẽ bị giết sau các Pod
BestEffort. - Ví dụ:yaml
resources: requests: memory: "64Mi" cpu: "250m" limits: memory: "128Mi" cpu: "500m"
- Điều kiện: Ít nhất một container trong Pod có
BestEffort(Nỗ lực tốt nhất):- Điều kiện: Không có bất kỳ container nào trong Pod có
requestshoặclimits. - Đặc điểm: Đây là các Pod có độ ưu tiên thấp nhất. Chúng sẽ là những Pod đầu tiên bị giết khi Node hết tài nguyên. Chỉ nên dùng cho các tác vụ có độ ưu tiên thấp, không quan trọng.
- Điều kiện: Không có bất kỳ container nào trong Pod có
9.6. ResourceQuota và LimitRange: Giới hạn tài nguyên ở mức Namespace
Requests và limits được đặt ở cấp độ container. Nhưng làm thế nào để một Admin có thể kiểm soát tổng lượng tài nguyên mà một team hoặc một dự án được phép sử dụng?
ResourceQuota:- Cho phép Admin đặt ra giới hạn tổng tài nguyên cho một
namespace. - Ví dụ: Namespace
team-achỉ được phép yêu cầu tổng cộng 20 core CPU và 64GiB Memory, và chỉ được tạo tối đa 10Service. - Nếu việc tạo một tài nguyên mới (Pod, Service) làm vượt quá quota, yêu cầu sẽ bị từ chối.
- Cho phép Admin đặt ra giới hạn tổng tài nguyên cho một
LimitRange:- Cho phép Admin đặt ra các giới hạn mặc định, giới hạn tối thiểu/tối đa cho các tài nguyên trong một
namespace. - Ví dụ:
- Nếu một Pod được tạo mà không có
requests/limits, nó sẽ tự động được gán giá trị mặc định. - Đảm bảo không ai có thể tạo một Pod yêu cầu quá nhiều tài nguyên (ví dụ: 100GiB Memory).
- Đảm bảo mọi Pod đều có
requesttối thiểu.
- Nếu một Pod được tạo mà không có
- Cho phép Admin đặt ra các giới hạn mặc định, giới hạn tối thiểu/tối đa cho các tài nguyên trong một
Hai công cụ này rất quan trọng cho các môi trường đa người dùng (multi-tenant), giúp đảm bảo sự công bằng và ổn định cho toàn bộ cluster.
Kết luận Chương 9: Việc cấu hình Health Checks và Resource Management là một bước chuyển từ "chạy được" sang "chạy tốt và đáng tin cậy". Liveness, Readiness, và Startup probes là những người bảo vệ thầm lặng, đảm bảo ứng dụng của bạn luôn khỏe mạnh và các bản cập nhật diễn ra an toàn. Requests và Limits là nền tảng của sự ổn định và khả năng dự đoán trong một môi trường chia sẻ tài nguyên. Nắm vững các khái niệm này, bạn đã tiến một bước dài trên con đường trở thành một kỹ sư vận hành ứng dụng chuyên nghiệp trên Kubernetes. Tiếp theo, chúng ta sẽ khám phá bộ công cụ cần thiết để "nhìn" vào bên trong hệ thống: Logging, Monitoring và Debugging.
Chương 10: Logging, Monitoring và Debugging
Chúng ta đã học cách triển khai, kết nối, cấu hình và quản lý tài nguyên cho ứng dụng. Nhưng khi hệ thống đã chạy, làm thế nào chúng ta biết được điều gì đang thực sự xảy ra bên trong? Khi có lỗi, làm thế nào để tìm ra nguyên nhân? Đây là lúc bộ ba "thần thánh" của vận hành hệ thống vào cuộc: Logging (Ghi log), Monitoring (Giám sát), và Debugging (Gỡ lỗi).
Trong một hệ thống phân tán và năng động như Kubernetes, việc "quan sát" (Observability) không còn là một tùy chọn, mà là một yêu cầu bắt buộc.
10.1. Logging
Logging là việc ghi lại các sự kiện rời rạc, theo thời gian đã xảy ra trong ứng dụng. Mỗi dòng log là một "dấu vết" về một hành động hoặc một sự kiện cụ thể.
10.1.1. Triết lý Logging trong Kubernetes: Ghi log ra stdout và stderr
Trong môi trường container, cách tiếp cận tốt nhất và đơn giản nhất là để ứng dụng của bạn ghi log trực tiếp ra hai luồng (stream) tiêu chuẩn: standard output (stdout) cho các log thông thường và standard error (stderr) cho các log lỗi.
Tại sao lại như vậy?
- Tách biệt mối quan tâm: Ứng dụng của bạn chỉ cần tập trung vào việc tạo ra log. Nó không cần quan tâm đến việc log sẽ được lưu trữ ở đâu, xoay vòng (rotate) như thế nào, hay gửi đi đâu. Việc định tuyến và xử lý log là nhiệm vụ của hạ tầng.
- Tính di động: Ứng dụng của bạn không bị phụ thuộc vào một hệ thống file cụ thể. Nó có thể chạy ở bất cứ đâu.
- Tích hợp tự nhiên: Container runtime (như
containerd) vàkubeletđược thiết kế để tự động thu thập các luồngstdoutvàstderrnày.
Khi bạn chạy lệnh kubectl logs <tên-pod>, bạn đang thực chất đọc lại các bản ghi mà kubelet đã thu thập từ stdout và stderr của container.
10.1.2. Kiến trúc logging trong Kubernetes
Việc dùng kubectl logs chỉ phù hợp để xem log nhanh của một Pod. Khi Pod bị xóa, log của nó cũng biến mất. Để có một hệ thống logging bền bỉ và tập trung, chúng ta cần một giải pháp ở cấp độ cluster. Có hai kiến trúc chính:
1. Node-level Logging Agent (Agent ghi log ở cấp độ Node): Đây là kiến trúc phổ biến và được khuyến khích nhất.
- Cách hoạt động: Một agent chuyên dụng (như
Fluentd,Promtail,Vector) được triển khai trên mỗi Worker Node dưới dạng mộtDaemonSet. - Agent này sẽ tự động truy cập vào các file log mà
kubelettạo ra trên Node (thường ở/var/log/pods/...). - Nó sẽ đọc, xử lý (ví dụ: thêm metadata như tên Pod, namespace), và gửi log đến một backend lưu trữ tập trung (như Elasticsearch, Loki, hoặc một dịch vụ cloud).
- Ưu điểm: Hiệu quả, tự động thu thập log từ tất cả các Pod trên Node mà không cần thay đổi ứng dụng.
2. Sidecar Logging Container: Kiến trúc này được sử dụng trong các trường hợp đặc biệt.
- Cách hoạt động: Một container "sidecar" được thêm vào mỗi Pod của ứng dụng.
- Ứng dụng chính có thể ghi log vào một file trong một
Volumedùng chung, hoặc sidecar có thể "đuôi" (tail)stdout/stderrcủa ứng dụng chính. - Container sidecar sau đó sẽ chịu trách nhiệm gửi log đến backend tập trung.
- Trường hợp sử dụng:
- Khi ứng dụng không thể dễ dàng sửa đổi để ghi ra
stdout/stderr(ví dụ: một ứng dụng cũ ghi vào file cố định). - Khi bạn cần xử lý log một cách chuyên biệt cho từng ứng dụng.
- Khi ứng dụng không thể dễ dàng sửa đổi để ghi ra
- Nhược điểm: Tốn nhiều tài nguyên hơn (mỗi Pod có thêm một container), phức tạp hơn để cấu hình.
10.1.3. Bộ công cụ EFK/Loki-Promtail
EFK Stack (Elasticsearch, Fluentd, Kibana):
- Fluentd: Agent (
DaemonSet) thu thập, xử lý và gửi log. - Elasticsearch: Một công cụ tìm kiếm và phân tích mạnh mẽ, dùng để lưu trữ và đánh chỉ mục (index) log.
- Kibana: Giao diện web để tìm kiếm, trực quan hóa và phân tích log trong Elasticsearch.
- Đây là một bộ công cụ rất mạnh mẽ nhưng cũng khá phức tạp và tốn tài nguyên (đặc biệt là Elasticsearch).
- Fluentd: Agent (
Loki, Promtail, và Grafana:
- Promtail: Một agent cực kỳ nhẹ (
DaemonSet) được thiết kế chuyên biệt để thu thập log và gửi cho Loki. - Loki: Backend lưu trữ log, được phát triển bởi Grafana Labs. Triết lý của Loki là "chỉ đánh chỉ mục metadata, không phải nội dung log". Nó chỉ index các
label(giống Prometheus) nhưpod,namespace,app. Điều này giúp Loki cực kỳ hiệu quả về chi phí lưu trữ và tài nguyên so với Elasticsearch. - Grafana: Giao diện để truy vấn (bằng ngôn ngữ LogQL) và hiển thị log từ Loki, cũng như metrics từ Prometheus, tạo ra một nền tảng quan sát hợp nhất.
- Bộ công cụ này đang ngày càng trở nên phổ biến vì sự đơn giản và hiệu quả của nó.
- Promtail: Một agent cực kỳ nhẹ (
10.2. Monitoring
Nếu logging cho chúng ta biết "điều gì đã xảy ra", thì monitoring cho chúng ta biết "hệ thống đang hoạt động như thế nào" ở một góc độ tổng hợp. Monitoring tập trung vào việc thu thập, xử lý và hiển thị các chỉ số (metrics) dạng số theo thời gian.
10.2.1. Các chỉ số quan trọng cần theo dõi
Có hai phương pháp luận phổ biến để xác định những gì cần theo dõi:
- The RED Method (Rate, Errors, Duration): Dành cho các hệ thống dựa trên request.
- Rate: Số lượng request mỗi giây.
- Errors: Số lượng request thất bại mỗi giây.
- Duration: Thời gian xử lý mỗi request (thường là phân vị 95, 99).
- The USE Method (Utilization, Saturation, Errors): Dành cho việc theo dõi tài nguyên.
- Utilization: Mức độ sử dụng tài nguyên (ví dụ: CPU đang sử dụng 80%).
- Saturation: Mức độ "bận rộn" của tài nguyên, thường biểu thị qua hàng đợi (ví dụ: CPU load average).
- Errors: Số lượng lỗi của tài nguyên (ví dụ: lỗi mạng, lỗi ổ đĩa).
10.2.2. Kiến trúc Metrics trong Kubernetes
cAdvisor: Một thành phần được tích hợp sẵn trongkubelet. Nó tự động thu thập các metrics cơ bản về hiệu suất của container và Node (sử dụng CPU, memory, network, file system).Metrics Server: Một thành phần cluster-level, thu thập dữ liệu từ tất cả cáccAdvisorvà tổng hợp chúng lại. Nó cung cấp một API tối giản (metrics.k8s.io) cho phép bạn xem mức sử dụng tài nguyên hiện tại. Đây là nguồn dữ liệu cho các lệnh nhưkubectl top podvàkubectl top node.Metrics Serverkhông lưu trữ dữ liệu lịch sử.- Hệ thống Monitoring đầy đủ (Prometheus): Để có thể giám sát một cách toàn diện, lưu trữ dữ liệu lịch sử và thiết lập cảnh báo, bạn cần một giải pháp như Prometheus.
10.2.3. Prometheus và Grafana: Tiêu chuẩn vàng của monitoring
Prometheus:
- Là một dự án tốt nghiệp của CNCF và là tiêu chuẩn de facto cho monitoring trong hệ sinh thái cloud-native.
- Mô hình Pull-based: Prometheus Server định kỳ "kéo" (scrape) metrics từ các endpoint HTTP (
/metrics) mà các ứng dụng hoặc các "exporter" phơi bày ra. - Service Discovery: Prometheus tích hợp hoàn hảo với Kubernetes. Nó có thể tự động phát hiện tất cả các Pod, Service, Node trong cluster và tìm ra các endpoint
/metricsđể scrape. - PromQL: Một ngôn ngữ truy vấn cực kỳ mạnh mẽ và linh hoạt để bạn có thể tổng hợp, tính toán và phân tích dữ liệu time-series.
- Alertmanager: Một thành phần đi kèm để xử lý việc gửi cảnh báo (alert) qua email, Slack, PagerDuty, v.v.
Grafana:
- Là công cụ trực quan hóa hàng đầu cho dữ liệu time-series.
- Nó có thể kết nối với Prometheus (và nhiều nguồn dữ liệu khác) để tạo ra các dashboard đẹp mắt, tương tác, giúp bạn dễ dàng theo dõi sức khỏe của hệ thống.
10.3. Debugging
Khi logging và monitoring cho thấy có vấn đề, bạn cần các công cụ để "lặn sâu" vào hệ thống và tìm ra gốc rễ của vấn đề.
10.3.1. Bộ tứ kubectl cho Debugging
kubectl logs: Luôn là điểm bắt đầu. Xem log của Pod để tìm các thông báo lỗi hoặc stack trace.kubectl logs <pod-name>kubectl logs -f <pod-name>(theo dõi log)kubectl logs --previous <pod-name>(xem log của container đã bị khởi động lại)
kubectl describe pod <pod-name>: Cung cấp một "bản tóm tắt" toàn diện về Pod. Hãy đặc biệt chú ý đến phần Events ở cuối cùng. Phần này ghi lại các sự kiện quan trọng trong vòng đời của Pod, ví dụ như "Failed to pull image", "Liveness probe failed", "Node is out of memory". Rất nhiều vấn đề có thể được chẩn đoán chỉ bằng cách đọc Events.kubectl get events --sort-by='.lastTimestamp': Xem danh sách tất cả các sự kiện gần đây trong namespace, giúp bạn có một cái nhìn tổng quan về những gì đang xảy ra.kubectl exec -it <pod-name> -- /bin/bash: "Nhảy" vào bên trong một container đang chạy. Đây là công cụ cực kỳ mạnh mẽ để:- Kiểm tra xem các file cấu hình đã được mount đúng chưa (
ls,cat). - Kiểm tra kết nối mạng từ bên trong Pod (
ping,curl,netstat). - Kiểm tra các biến môi trường (
env).
- Kiểm tra xem các file cấu hình đã được mount đúng chưa (
10.3.2. Debugging các lỗi Pod phổ biến
Pending: Pod bị kẹt ở trạng tháiPending. Dùngkubectl describeđể xem lý do.- Lý do phổ biến: Cluster không đủ tài nguyên (CPU/Memory) để đáp ứng
requestscủa Pod; Pod yêu cầu mộtVolumekhông tồn tại hoặc không có sẵn;taints/tolerationskhông khớp.
- Lý do phổ biến: Cluster không đủ tài nguyên (CPU/Memory) để đáp ứng
ImagePullBackOff/ErrImagePull:kubeletkhông thể kéo container image.- Lý do phổ biến: Sai tên image hoặc tag; image không tồn tại; cần thông tin xác thực để kéo image từ private registry nhưng
Secret(loạidockerconfigjson) chưa được cung cấp.
- Lý do phổ biến: Sai tên image hoặc tag; image không tồn tại; cần thông tin xác thực để kéo image từ private registry nhưng
CrashLoopBackOff: Container khởi động, bị crash, rồikubeletlại cố gắng khởi động lại nó, tạo thành một vòng lặp.- Đây là một triệu chứng, không phải nguyên nhân. Nguyên nhân thực sự là do ứng dụng của bạn bị crash ngay khi khởi động.
- Cách debug: Dùng
kubectl logs --previous <pod-name>để xem log của lần chạy trước khi nó bị crash. Rất có thể bạn sẽ thấy một lỗi nghiêm trọng (panic, unhandled exception) ở đó.
OOMKilled: Container đã cố gắng sử dụng nhiều Memory hơn mứclimitcủa nó và đã bịkubeletgiết.- Cách debug: Tăng
memory limithoặc tối ưu hóa việc sử dụng memory của ứng dụng.
- Cách debug: Tăng
10.3.3. Ephemeral Containers: Debugging live
Đôi khi, bạn cần debug một Pod đang chạy nhưng image của nó lại không chứa các công cụ cần thiết (như curl, net-tools). Việc exec vào và cài đặt chúng sẽ làm thay đổi container.
Ephemeral Containers (tính năng ổn định từ Kubernetes 1.25) cho phép bạn "gắn" một container gỡ lỗi tạm thời vào một Pod đang chạy mà không cần khởi động lại nó.
# Gắn một container tên 'debugger' dùng image 'busybox' vào pod 'my-pod'
kubectl debug -it my-pod --image=busybox --target=my-app-containerLệnh này sẽ tạo một container mới trong Pod, chia sẻ chung network và process namespace với container my-app-container, cho phép bạn sử dụng các công cụ từ busybox để kiểm tra môi trường của container chính.
10.3.4. kubectl port-forward: Truy cập ứng dụng trực tiếp
Khi bạn muốn truy cập trực tiếp vào một port của Pod từ máy local của mình để test hoặc debug (ví dụ: kết nối một debugger từ IDE, truy cập vào một web UI nội bộ), port-forward là công cụ dành cho bạn.
# Chuyển tiếp port 8080 trên máy local đến port 80 của pod 'my-web-pod'
kubectl port-forward my-web-pod 8080:80Bây giờ, bạn có thể mở trình duyệt và truy cập http://localhost:8080, traffic sẽ được chuyển tiếp an toàn đến Pod trong cluster.
Kết luận Chương 10: Logging, Monitoring, và Debugging là ba trụ cột của khả năng quan sát hệ thống. Bằng cách áp dụng triết lý ghi log ra stdout/stderr, triển khai các hệ thống giám sát mạnh mẽ như Prometheus, và thành thạo các công cụ gỡ lỗi của kubectl, bạn có thể tự tin vận hành và duy trì sự ổn định cho các ứng dụng phức tạp trên Kubernetes. Với những kỹ năng này, bạn không chỉ là một người xây dựng ứng dụng, mà còn là một người "bác sĩ" có khả-năng-chẩn-đoán và "chữa bệnh" cho hệ thống của mình.
Chương 11: Tối Ưu Hóa Quy Trình Phát Triển (Development Workflow)
- Chương 11.1. Vòng lặp phát triển: Code -> Build -> Deploy -> Test.
- Chương 11.2.
Skaffold: Tự động hóa vòng lặp phát triển trên Kubernetes. - Chương 11.3.
Telepresence: Phát triển và debug service cục bộ như thể nó đang chạy trong cluster. - Chương 11.4.
DevSpace: Một lựa chọn mạnh mẽ khác. - Chương 11.5. Xây dựng Docker image hiệu quả cho Kubernetes.
Phần IV: Helm - Trình Quản Lý Gói cho Kubernetes
Chương 12: Giới Thiệu về Helm
- 12.1. Helm là gì và tại sao nó cần thiết?
- 12.2. Các khái niệm cốt lõi: Chart, Release, Repository.
- 12.3. Kiến trúc Helm (Helm 3).
- 12.4. Cài đặt và cấu hình Helm.
Chương 13: Sử Dụng Helm Chart
- 13.1. Tìm kiếm Chart từ các repository (Artifact Hub).
- 13.2. Cài đặt một Chart (
helm install). - 13.3. Tùy chỉnh Chart với file
values.yaml. - 13.4. Quản lý các Release (
helm list,helm status,helm upgrade,helm rollback,helm uninstall).
Chương 14: Xây Dựng Helm Chart của Riêng Bạn
- 14.1. Cấu trúc của một Chart (
Chart.yaml,values.yaml,templates/,charts/). - 14.2. Go Templating Engine: Ngôn ngữ của Helm.
- 14.2.1. Biến, hàm, và pipelines.
- 14.2.2. Các đối tượng tích hợp sẵn (
.Values,.Release,.Chart). - 14.2.3. Luồng điều khiển (if/else, range).
- 14.2.4. Named Templates (
_helpers.tpl).
- 14.3. Quản lý các Chart phụ thuộc (Dependencies).
- 14.4.
helm lintvàhelm template: Debugging Chart của bạn. - 15.5. Đóng gói và chia sẻ Chart (
helm package, Chart Repository).
- 14.1. Cấu trúc của một Chart (
Phần V: Các Chủ Đề Nâng Cao và Mở Rộng
Chương 15: Bảo Mật trong Kubernetes cho Developer
- 15.1.
RBAC(Role-Based Access Control): Ai được làm gì?- 15.1.1.
Role,ClusterRole,RoleBinding,ClusterRoleBinding.
- 15.1.1.
- 15.2.
ServiceAccount: Định danh cho ứng dụng. - 15.3.
PodSecurityPolicy/Pod Security Admission. - 15.4.
NetworkPolicy: Tường lửa cho Pods. - 15.5. Quét lỗ hổng bảo mật trong container image.
- 15.1.
Chương 16: CI/CD với Kubernetes
- 16.1. Tổng quan về CI/CD trong thế giới Kubernetes.
- 16.2. Tích hợp Kubernetes với Jenkins.
- 16.3. Tích hợp Kubernetes với GitLab CI/CD.
- 16.4.
Argo CD: GitOps - "Infrastructure as Code" cho Kubernetes. - 16.5.
Flux CD: Một lựa chọn GitOps phổ biến khác.
Chương 17: Service Mesh - Quản Lý Giao Tiếp Giữa Các Service
- 17.1. Service Mesh là gì?
- 17.2.
Istio: Giới thiệu và kiến trúc. - 17.3.
Linkerd: Đơn giản và hiệu quả. - 17.4. Các tính năng chính: Traffic Management, Observability, Security.
Chương 18: Mở Rộng Kubernetes với Operators và CRDs
- 18.1.
Custom Resource Definitions(CRDs): Mở rộng Kubernetes API. - 18.2.
Operator Pattern: Tự động hóa quản lý ứng dụng phức tạp. - 18.3. Xây dựng một Operator đơn giản với
Operator SDKhoặcKubebuilder.
- 18.1.
Phụ Lục
- A: Bảng thuật ngữ Kubernetes.
- B: Tổng hợp các lệnh
kubectlhữu ích. - C: Các lỗi thường gặp và cách khắc phục.
- D: Tài liệu tham khảo và các khóa học đề xuất.
Phần III: Vận Hành và Tối Ưu Hóa cho Developer
Chương 9: Health Checks và Quản Lý Tài Nguyên
Việc triển khai được một ứng dụng chỉ là bước khởi đầu. Để vận hành một hệ thống đáng tin cậy, chúng ta cần trả lời hai câu hỏi quan trọng:
- Làm sao để biết ứng dụng của chúng ta vẫn đang hoạt động bình thường và sẵn sàng phục vụ người dùng?
- Làm sao để đảm bảo ứng dụng có đủ tài nguyên (CPU, Memory) để chạy, nhưng cũng không chiếm dụng quá mức gây ảnh hưởng đến các ứng dụng khác?
Chương này sẽ đi sâu vào hai cơ chế cốt lõi của Kubernetes giúp giải quyết những vấn đề trên: Health Checks (Probes) và Resource Management (Requests & Limits).
9.1. Liveness Probe: Pod của bạn có còn "sống"?
Vấn đề: Đôi khi, một ứng dụng vẫn đang chạy (tiến trình process vẫn tồn tại) nhưng lại rơi vào trạng thái không thể hoạt động được, ví dụ như bị deadlock, hết bộ nhớ, hoặc một vòng lặp vô hạn. Từ bên ngoài, tiến trình vẫn "sống", nhưng nó không còn khả năng xử lý yêu cầu hay làm bất cứ việc gì hữu ích.
Giải pháp: Liveness Probe (Thăm dò sự sống) là một cơ chế cho phép kubelet kiểm tra xem một container có còn hoạt động đúng cách hay không.
- Nếu Liveness Probe thành công:
kubeletkhông làm gì cả. - Nếu Liveness Probe thất bại:
kubeletsẽ giết (kill) container đó và khởi động lại nó theorestartPolicycủa Pod.
Hành động "giết và khởi động lại" này cực kỳ hiệu quả trong việc tự động phục hồi các ứng dụng bị treo.
Kubernetes cung cấp ba cách để thực hiện một probe:
- HTTP Probe (
httpGet):kubeletgửi một yêu cầu HTTP GET đến một endpoint cụ thể trong container của bạn. Nếu nhận được mã trả về trong khoảng 200-399, probe được coi là thành công. - TCP Probe (
tcpSocket):kubeletcố gắng mở một kết nối TCP đến một port cụ thể trong container. Nếu kết nối thành công, probe được coi là thành công. - Command Probe (
exec):kubeletthực thi một lệnh bên trong container. Nếu lệnh trả về exit code 0, probe được coi là thành công.
Ví dụ về Liveness Probe:
apiVersion: v1
kind: Pod
metadata:
name: liveness-pod
spec:
containers:
- name: my-app
image: my-app-image
livenessProbe:
httpGet:
path: /healthz # Endpoint kiểm tra sức khỏe
port: 8080
initialDelaySeconds: 15 # Chờ 15 giây sau khi container khởi động mới bắt đầu probe
periodSeconds: 20 # Thực hiện probe mỗi 20 giây
timeoutSeconds: 1 # Coi là thất bại nếu không nhận được phản hồi sau 1 giây
failureThreshold: 3 # Coi là thất bại thực sự sau 3 lần probe liên tiếp thất bại9.2. Readiness Probe: Pod đã sẵn sàng nhận request chưa?
Vấn đề: Một ứng dụng có thể đã khởi động (liveness probe thành công) nhưng chưa sẵn sàng để nhận traffic. Ví dụ:
- Một ứng dụng Java cần thời gian để khởi tạo Spring context, nạp dữ liệu vào cache.
- Một ứng dụng cần kết nối đến database và thực hiện các migration ban đầu.
Nếu Service gửi traffic đến Pod ngay khi nó vừa khởi động, người dùng có thể sẽ gặp lỗi.
Giải pháp: Readiness Probe (Thăm dò sự sẵn sàng) được dùng để cho Kubernetes biết khi nào một container đã sẵn sàng để bắt đầu nhận traffic.
- Nếu Readiness Probe thành công:
kubeletsẽ đánh dấu Pod làReady.Servicesẽ bắt đầu đưa Pod này vào danh sách các endpoint hợp lệ và gửi traffic đến nó. - Nếu Readiness Probe thất bại:
kubeletsẽ đánh dấu Pod làNotReady.Servicesẽ xóa Pod này khỏi danh sách endpoint. Traffic sẽ không được gửi đến nó nữa cho đến khi probe thành công trở lại.
Quan trọng là, nếu Readiness Probe thất bại, kubelet sẽ không khởi động lại container. Nó chỉ tạm thời "cách ly" Pod ra khỏi luồng traffic.
Tại sao Readiness Probe lại quan trọng cho Rolling Update? Khi bạn thực hiện một Deployment rolling update, Kubernetes sẽ chỉ coi một Pod mới là "sẵn sàng" khi Readiness Probe của nó thành công. Điều này đảm bảo rằng Pod mới chỉ nhận traffic khi nó đã thực sự sẵn sàng 100%, giúp quá trình cập nhật diễn ra mượt mà không gây lỗi cho người dùng (zero-downtime deployment).
Ví dụ về Readiness Probe: Cấu hình của Readiness Probe hoàn toàn tương tự Liveness Probe.
apiVersion: v1
kind: Pod
metadata:
name: readiness-pod
spec:
containers:
- name: my-app
image: my-app-image
readinessProbe:
httpGet:
path: /ready
port: 8080
initialDelaySeconds: 5
periodSeconds: 10Best Practice: Luôn luôn định nghĩa cả
LivenessvàReadinessprobe.Livenessđể khởi động lại ứng dụng bị treo,Readinessđể đảm bảo cập nhật an toàn và không gửi traffic đến ứng dụng chưa sẵn sàng. Endpoint củaReadinessprobe thường phức tạp hơn, có thể cần kiểm tra cả kết nối đến database, message queue, v.v.
9.3. Startup Probe: Dành cho các ứng dụng khởi động chậm
Vấn đề: Một số ứng dụng (đặc biệt là các ứng dụng Java cũ hoặc các ứng dụng cần thực hiện nhiều tác vụ nặng khi khởi động) có thể mất vài phút để bắt đầu. Nếu initialDelaySeconds của Liveness Probe quá ngắn, kubelet có thể giết chết container trước khi nó kịp khởi động xong, gây ra một vòng lặp khởi động lại không hồi kết (CrashLoopBackOff).
Giải pháp: Startup Probe (Thăm dò khởi động) được thiết kế đặc biệt cho trường hợp này.
- Khi
Startup Probeđược định nghĩa, tất cả các probe khác sẽ bị vô hiệu hóa cho đến khiStartup Probethành công. Startup Probecó một khoảng thời gian dài (failureThreshold*periodSeconds) để hoàn thành.- Nếu Startup Probe thành công:
kubeletsẽ bắt đầu thực hiệnLivenessvàReadinessprobe như bình thường. - Nếu Startup Probe thất bại (vượt quá thời gian cho phép):
kubeletsẽ giết và khởi động lại container.
Ví dụ về Startup Probe:
startupProbe:
httpGet:
path: /healthz
port: 8080
failureThreshold: 30 # Thử lại 30 lần
periodSeconds: 10 # Mỗi lần cách nhau 10 giây
# => Container có tổng cộng 30 * 10 = 300 giây (5 phút) để khởi động.9.4. Requests và Limits: Quản lý CPU và Memory
Trong một cluster chia sẻ, việc quản lý tài nguyên là tối quan trọng. Kubernetes cho phép bạn chỉ định lượng CPU và Memory mà mỗi container cần và được phép sử dụng thông qua hai tham số: requests và limits.
requests (Yêu cầu):
- Ý nghĩa: Lượng tài nguyên được đảm bảo (guaranteed) cho container.
- Cách hoạt động:
- Memory Request: Kubernetes đảm bảo container sẽ luôn có ít nhất lượng memory này.
- CPU Request: Kubernetes đảm bảo container sẽ nhận được phần CPU tương ứng. CPU là tài nguyên có thể "nén" được (compressible), nên nếu có CPU nhàn rỗi, container có thể dùng nhiều hơn mức request.
- Vai trò với Scheduler:
kube-schedulersử dụngrequestsđể quyết định đặt Pod ở đâu. Nó sẽ chỉ đặt Pod lên một Node nếu Node đó có đủ tài nguyên chưa được cấp phát để đáp ứngrequestscủa Pod.
limits (Giới hạn):
- Ý nghĩa: Lượng tài nguyên tối đa mà container được phép sử dụng.
- Cách hoạt động:
- Memory Limit: Nếu container cố gắng sử dụng nhiều memory hơn
limit, nó sẽ bị giết với lỗi OOMKilled (Out of Memory). - CPU Limit: Nếu container cố gắng sử dụng nhiều CPU hơn
limit, nó sẽ bị điều tiết (throttled), tức là hiệu năng sẽ bị giảm xuống để không vượt quá giới hạn. Container sẽ không bị giết.
- Memory Limit: Nếu container cố gắng sử dụng nhiều memory hơn
Đơn vị đo lường:
- Memory:
Ki(Kibibyte),Mi(Mebibyte),Gi(Gibibyte),Ti(Tebibyte). - CPU:
m(millicpu hoặc millicore).1000mtương đương với 1 vCPU/core.500mlà nửa core.
Ví dụ:
resources:
requests:
memory: "64Mi"
cpu: "250m" # 0.25 core
limits:
memory: "128Mi"
cpu: "500m" # 0.5 coreBest Practice: Luôn luôn đặt
requestsvàlimitscho mọi container trong môi trường production. Điều này giúp Scheduler đưa ra quyết định tốt hơn, tránh tình trạng "hàng xóm ồn ào" (một Pod dùng quá nhiều tài nguyên ảnh hưởng đến các Pod khác), và làm cho cluster hoạt động ổn định hơn.
9.5. Quality of Service (QoS) Classes
Dựa trên cách bạn đặt requests và limits, Kubernetes sẽ tự động gán cho Pod của bạn một trong ba lớp Chất lượng Dịch vụ (QoS). Lớp QoS này quyết định Pod nào sẽ bị giết trước tiên khi Node cạn kiệt tài nguyên (đặc biệt là Memory).
Guaranteed(Đảm bảo):- Điều kiện: Mọi container trong Pod phải có cả
memory requestvàmemory limit, và chúng phải bằng nhau. Tương tự cho CPU. - Đặc điểm: Đây là các Pod có độ ưu tiên cao nhất. Chúng sẽ là những Pod cuối cùng bị giết nếu Node hết tài nguyên.
- Ví dụ:yaml
resources: requests: memory: "128Mi" cpu: "500m" limits: memory: "128Mi" cpu: "500m"
- Điều kiện: Mọi container trong Pod phải có cả
Burstable(Có thể bùng nổ):- Điều kiện: Ít nhất một container trong Pod có
requestnhưnglimitlớn hơnrequest, hoặc chỉ córequestmà không cólimit. - Đặc điểm: Các Pod này được phép "bùng nổ" sử dụng nhiều tài nguyên hơn mức request nếu có tài nguyên nhàn rỗi trên Node. Chúng có độ ưu tiên trung bình và sẽ bị giết sau các Pod
BestEffort. - Ví dụ:yaml
resources: requests: memory: "64Mi" cpu: "250m" limits: memory: "128Mi" cpu: "500m"
- Điều kiện: Ít nhất một container trong Pod có
BestEffort(Nỗ lực tốt nhất):- Điều kiện: Không có bất kỳ container nào trong Pod có
requestshoặclimits. - Đặc điểm: Đây là các Pod có độ ưu tiên thấp nhất. Chúng sẽ là những Pod đầu tiên bị giết khi Node hết tài nguyên. Chỉ nên dùng cho các tác vụ có độ ưu tiên thấp, không quan trọng.
- Điều kiện: Không có bất kỳ container nào trong Pod có
9.6. ResourceQuota và LimitRange: Giới hạn tài nguyên ở mức Namespace
Requests và limits được đặt ở cấp độ container. Nhưng làm thế nào để một Admin có thể kiểm soát tổng lượng tài nguyên mà một team hoặc một dự án được phép sử dụng?
ResourceQuota:- Cho phép Admin đặt ra giới hạn tổng tài nguyên cho một
namespace. - Ví dụ: Namespace
team-achỉ được phép yêu cầu tổng cộng 20 core CPU và 64GiB Memory, và chỉ được tạo tối đa 10Service. - Nếu việc tạo một tài nguyên mới (Pod, Service) làm vượt quá quota, yêu cầu sẽ bị từ chối.
- Cho phép Admin đặt ra giới hạn tổng tài nguyên cho một
LimitRange:- Cho phép Admin đặt ra các giới hạn mặc định, giới hạn tối thiểu/tối đa cho các tài nguyên trong một
namespace. - Ví dụ:
- Nếu một Pod được tạo mà không có
requests/limits, nó sẽ tự động được gán giá trị mặc định. - Đảm bảo không ai có thể tạo một Pod yêu cầu quá nhiều tài nguyên (ví dụ: 100GiB Memory).
- Đảm bảo mọi Pod đều có
requesttối thiểu.
- Nếu một Pod được tạo mà không có
- Cho phép Admin đặt ra các giới hạn mặc định, giới hạn tối thiểu/tối đa cho các tài nguyên trong một
Hai công cụ này rất quan trọng cho các môi trường đa người dùng (multi-tenant), giúp đảm bảo sự công bằng và ổn định cho toàn bộ cluster.
Kết luận Chương 9: Việc cấu hình Health Checks và Resource Management là một bước chuyển từ "chạy được" sang "chạy tốt và đáng tin cậy". Liveness, Readiness, và Startup probes là những người bảo vệ thầm lặng, đảm bảo ứng dụng của bạn luôn khỏe mạnh và các bản cập nhật diễn ra an toàn. Requests và Limits là nền tảng của sự ổn định và khả năng dự đoán trong một môi trường chia sẻ tài nguyên. Nắm vững các khái niệm này, bạn đã tiến một bước dài trên con đường trở thành một kỹ sư vận hành ứng dụng chuyên nghiệp trên Kubernetes. Tiếp theo, chúng ta sẽ khám phá bộ công cụ cần thiết để "nhìn" vào bên trong hệ thống: Logging, Monitoring và Debugging.
Chương 10: Logging, Monitoring và Debugging
Chúng ta đã học cách triển khai, kết nối, cấu hình và quản lý tài nguyên cho ứng dụng. Nhưng khi hệ thống đã chạy, làm thế nào chúng ta biết được điều gì đang thực sự xảy ra bên trong? Khi có lỗi, làm thế nào để tìm ra nguyên nhân? Đây là lúc bộ ba "thần thánh" của vận hành hệ thống vào cuộc: Logging (Ghi log), Monitoring (Giám sát), và Debugging (Gỡ lỗi).
Trong một hệ thống phân tán và năng động như Kubernetes, việc "quan sát" (Observability) không còn là một tùy chọn, mà là một yêu cầu bắt buộc.
10.1. Logging
Logging là việc ghi lại các sự kiện rời rạc, theo thời gian đã xảy ra trong ứng dụng. Mỗi dòng log là một "dấu vết" về một hành động hoặc một sự kiện cụ thể.
10.1.1. Triết lý Logging trong Kubernetes: Ghi log ra stdout và stderr
Trong môi trường container, cách tiếp cận tốt nhất và đơn giản nhất là để ứng dụng của bạn ghi log trực tiếp ra hai luồng (stream) tiêu chuẩn: standard output (stdout) cho các log thông thường và standard error (stderr) cho các log lỗi.
Tại sao lại như vậy?
- Tách biệt mối quan tâm: Ứng dụng của bạn chỉ cần tập trung vào việc tạo ra log. Nó không cần quan tâm đến việc log sẽ được lưu trữ ở đâu, xoay vòng (rotate) như thế nào, hay gửi đi đâu. Việc định tuyến và xử lý log là nhiệm vụ của hạ tầng.
- Tính di động: Ứng dụng của bạn không bị phụ thuộc vào một hệ thống file cụ thể. Nó có thể chạy ở bất cứ đâu.
- Tích hợp tự nhiên: Container runtime (như
containerd) vàkubeletđược thiết kế để tự động thu thập các luồngstdoutvàstderrnày.
Khi bạn chạy lệnh kubectl logs <tên-pod>, bạn đang thực chất đọc lại các bản ghi mà kubelet đã thu thập từ stdout và stderr của container.
10.1.2. Kiến trúc logging trong Kubernetes
Việc dùng kubectl logs chỉ phù hợp để xem log nhanh của một Pod. Khi Pod bị xóa, log của nó cũng biến mất. Để có một hệ thống logging bền bỉ và tập trung, chúng ta cần một giải pháp ở cấp độ cluster. Có hai kiến trúc chính:
1. Node-level Logging Agent (Agent ghi log ở cấp độ Node): Đây là kiến trúc phổ biến và được khuyến khích nhất.
- Cách hoạt động: Một agent chuyên dụng (như
Fluentd,Promtail,Vector) được triển khai trên mỗi Worker Node dưới dạng mộtDaemonSet. - Agent này sẽ tự động truy cập vào các file log mà
kubelettạo ra trên Node (thường ở/var/log/pods/...). - Nó sẽ đọc, xử lý (ví dụ: thêm metadata như tên Pod, namespace), và gửi log đến một backend lưu trữ tập trung (như Elasticsearch, Loki, hoặc một dịch vụ cloud).
- Ưu điểm: Hiệu quả, tự động thu thập log từ tất cả các Pod trên Node mà không cần thay đổi ứng dụng.
2. Sidecar Logging Container: Kiến trúc này được sử dụng trong các trường hợp đặc biệt.
- Cách hoạt động: Một container "sidecar" được thêm vào mỗi Pod của ứng dụng.
- Ứng dụng chính có thể ghi log vào một file trong một
Volumedùng chung, hoặc sidecar có thể "đuôi" (tail)stdout/stderrcủa ứng dụng chính. - Container sidecar sau đó sẽ chịu trách nhiệm gửi log đến backend tập trung.
- Trường hợp sử dụng:
- Khi ứng dụng không thể dễ dàng sửa đổi để ghi ra
stdout/stderr(ví dụ: một ứng dụng cũ ghi vào file cố định). - Khi bạn cần xử lý log một cách chuyên biệt cho từng ứng dụng.
- Khi ứng dụng không thể dễ dàng sửa đổi để ghi ra
- Nhược điểm: Tốn nhiều tài nguyên hơn (mỗi Pod có thêm một container), phức tạp hơn để cấu hình.
10.1.3. Bộ công cụ EFK/Loki-Promtail
EFK Stack (Elasticsearch, Fluentd, Kibana):
- Fluentd: Agent (
DaemonSet) thu thập, xử lý và gửi log. - Elasticsearch: Một công cụ tìm kiếm và phân tích mạnh mẽ, dùng để lưu trữ và đánh chỉ mục (index) log.
- Kibana: Giao diện web để tìm kiếm, trực quan hóa và phân tích log trong Elasticsearch.
- Đây là một bộ công cụ rất mạnh mẽ nhưng cũng khá phức tạp và tốn tài nguyên (đặc biệt là Elasticsearch).
- Fluentd: Agent (
Loki, Promtail, và Grafana:
- Promtail: Một agent cực kỳ nhẹ (
DaemonSet) được thiết kế chuyên biệt để thu thập log và gửi cho Loki. - Loki: Backend lưu trữ log, được phát triển bởi Grafana Labs. Triết lý của Loki là "chỉ đánh chỉ mục metadata, không phải nội dung log". Nó chỉ index các
label(giống Prometheus) nhưpod,namespace,app. Điều này giúp Loki cực kỳ hiệu quả về chi phí lưu trữ và tài nguyên so với Elasticsearch. - Grafana: Giao diện để truy vấn (bằng ngôn ngữ LogQL) và hiển thị log từ Loki, cũng như metrics từ Prometheus, tạo ra một nền tảng quan sát hợp nhất.
- Bộ công cụ này đang ngày càng trở nên phổ biến vì sự đơn giản và hiệu quả của nó.
- Promtail: Một agent cực kỳ nhẹ (
10.2. Monitoring
Nếu logging cho chúng ta biết "điều gì đã xảy ra", thì monitoring cho chúng ta biết "hệ thống đang hoạt động như thế nào" ở một góc độ tổng hợp. Monitoring tập trung vào việc thu thập, xử lý và hiển thị các chỉ số (metrics) dạng số theo thời gian.
10.2.1. Các chỉ số quan trọng cần theo dõi
Có hai phương pháp luận phổ biến để xác định những gì cần theo dõi:
- The RED Method (Rate, Errors, Duration): Dành cho các hệ thống dựa trên request.
- Rate: Số lượng request mỗi giây.
- Errors: Số lượng request thất bại mỗi giây.
- Duration: Thời gian xử lý mỗi request (thường là phân vị 95, 99).
- The USE Method (Utilization, Saturation, Errors): Dành cho việc theo dõi tài nguyên.
- Utilization: Mức độ sử dụng tài nguyên (ví dụ: CPU đang sử dụng 80%).
- Saturation: Mức độ "bận rộn" của tài nguyên, thường biểu thị qua hàng đợi (ví dụ: CPU load average).
- Errors: Số lượng lỗi của tài nguyên (ví dụ: lỗi mạng, lỗi ổ đĩa).
10.2.2. Kiến trúc Metrics trong Kubernetes
cAdvisor: Một thành phần được tích hợp sẵn trongkubelet. Nó tự động thu thập các metrics cơ bản về hiệu suất của container và Node (sử dụng CPU, memory, network, file system).Metrics Server: Một thành phần cluster-level, thu thập dữ liệu từ tất cả cáccAdvisorvà tổng hợp chúng lại. Nó cung cấp một API tối giản (metrics.k8s.io) cho phép bạn xem mức sử dụng tài nguyên hiện tại. Đây là nguồn dữ liệu cho các lệnh nhưkubectl top podvàkubectl top node.Metrics Serverkhông lưu trữ dữ liệu lịch sử.- Hệ thống Monitoring đầy đủ (Prometheus): Để có thể giám sát một cách toàn diện, lưu trữ dữ liệu lịch sử và thiết lập cảnh báo, bạn cần một giải pháp như Prometheus.
10.2.3. Prometheus và Grafana: Tiêu chuẩn vàng của monitoring
Prometheus:
- Là một dự án tốt nghiệp của CNCF và là tiêu chuẩn de facto cho monitoring trong hệ sinh thái cloud-native.
- Mô hình Pull-based: Prometheus Server định kỳ "kéo" (scrape) metrics từ các endpoint HTTP (
/metrics) mà các ứng dụng hoặc các "exporter" phơi bày ra. - Service Discovery: Prometheus tích hợp hoàn hảo với Kubernetes. Nó có thể tự động phát hiện tất cả các Pod, Service, Node trong cluster và tìm ra các endpoint
/metricsđể scrape. - PromQL: Một ngôn ngữ truy vấn cực kỳ mạnh mẽ và linh hoạt để bạn có thể tổng hợp, tính toán và phân tích dữ liệu time-series.
- Alertmanager: Một thành phần đi kèm để xử lý việc gửi cảnh báo (alert) qua email, Slack, PagerDuty, v.v.
Grafana:
- Là công cụ trực quan hóa hàng đầu cho dữ liệu time-series.
- Nó có thể kết nối với Prometheus (và nhiều nguồn dữ liệu khác) để tạo ra các dashboard đẹp mắt, tương tác, giúp bạn dễ dàng theo dõi sức khỏe của hệ thống.
10.3. Debugging
Khi logging và monitoring cho thấy có vấn đề, bạn cần các công cụ để "lặn sâu" vào hệ thống và tìm ra gốc rễ của vấn đề.
10.3.1. Bộ tứ kubectl cho Debugging
kubectl logs: Luôn là điểm bắt đầu. Xem log của Pod để tìm các thông báo lỗi hoặc stack trace.kubectl logs <pod-name>kubectl logs -f <pod-name>(theo dõi log)kubectl logs --previous <pod-name>(xem log của container đã bị khởi động lại)
kubectl describe pod <pod-name>: Cung cấp một "bản tóm tắt" toàn diện về Pod. Hãy đặc biệt chú ý đến phần Events ở cuối cùng. Phần này ghi lại các sự kiện quan trọng trong vòng đời của Pod, ví dụ như "Failed to pull image", "Liveness probe failed", "Node is out of memory". Rất nhiều vấn đề có thể được chẩn đoán chỉ bằng cách đọc Events.kubectl get events --sort-by='.lastTimestamp': Xem danh sách tất cả các sự kiện gần đây trong namespace, giúp bạn có một cái nhìn tổng quan về những gì đang xảy ra.kubectl exec -it <pod-name> -- /bin/bash: "Nhảy" vào bên trong một container đang chạy. Đây là công cụ cực kỳ mạnh mẽ để:- Kiểm tra xem các file cấu hình đã được mount đúng chưa (
ls,cat). - Kiểm tra kết nối mạng từ bên trong Pod (
ping,curl,netstat). - Kiểm tra các biến môi trường (
env).
- Kiểm tra xem các file cấu hình đã được mount đúng chưa (
10.3.2. Debugging các lỗi Pod phổ biến
Pending: Pod bị kẹt ở trạng tháiPending. Dùngkubectl describeđể xem lý do.- Lý do phổ biến: Cluster không đủ tài nguyên (CPU/Memory) để đáp ứng
requestscủa Pod; Pod yêu cầu mộtVolumekhông tồn tại hoặc không có sẵn;taints/tolerationskhông khớp.
- Lý do phổ biến: Cluster không đủ tài nguyên (CPU/Memory) để đáp ứng
ImagePullBackOff/ErrImagePull:kubeletkhông thể kéo container image.- Lý do phổ biến: Sai tên image hoặc tag; image không tồn tại; cần thông tin xác thực để kéo image từ private registry nhưng
Secret(loạidockerconfigjson) chưa được cung cấp.
- Lý do phổ biến: Sai tên image hoặc tag; image không tồn tại; cần thông tin xác thực để kéo image từ private registry nhưng
CrashLoopBackOff: Container khởi động, bị crash, rồikubeletlại cố gắng khởi động lại nó, tạo thành một vòng lặp.- Đây là một triệu chứng, không phải nguyên nhân. Nguyên nhân thực sự là do ứng dụng của bạn bị crash ngay khi khởi động.
- Cách debug: Dùng
kubectl logs --previous <pod-name>để xem log của lần chạy trước khi nó bị crash. Rất có thể bạn sẽ thấy một lỗi nghiêm trọng (panic, unhandled exception) ở đó.
OOMKilled: Container đã cố gắng sử dụng nhiều Memory hơn mứclimitcủa nó và đã bịkubeletgiết.- Cách debug: Tăng
memory limithoặc tối ưu hóa việc sử dụng memory của ứng dụng.
- Cách debug: Tăng
10.3.3. Ephemeral Containers: Debugging live
Đôi khi, bạn cần debug một Pod đang chạy nhưng image của nó lại không chứa các công cụ cần thiết (như curl, net-tools). Việc exec vào và cài đặt chúng sẽ làm thay đổi container.
Ephemeral Containers (tính năng ổn định từ Kubernetes 1.25) cho phép bạn "gắn" một container gỡ lỗi tạm thời vào một Pod đang chạy mà không cần khởi động lại nó.
# Gắn một container tên 'debugger' dùng image 'busybox' vào pod 'my-pod'
kubectl debug -it my-pod --image=busybox --target=my-app-containerLệnh này sẽ tạo một container mới trong Pod, chia sẻ chung network và process namespace với container my-app-container, cho phép bạn sử dụng các công cụ từ busybox để kiểm tra môi trường của container chính.
10.3.4. kubectl port-forward: Truy cập ứng dụng trực tiếp
Khi bạn muốn truy cập trực tiếp vào một port của Pod từ máy local của mình để test hoặc debug (ví dụ: kết nối một debugger từ IDE, truy cập vào một web UI nội bộ), port-forward là công cụ dành cho bạn.
# Chuyển tiếp port 8080 trên máy local đến port 80 của pod 'my-web-pod'
kubectl port-forward my-web-pod 8080:80Bây giờ, bạn có thể mở trình duyệt và truy cập http://localhost:8080, traffic sẽ được chuyển tiếp an toàn đến Pod trong cluster.
Kết luận Chương 10: Logging, Monitoring, và Debugging là ba trụ cột của khả năng quan sát hệ thống. Bằng cách áp dụng triết lý ghi log ra stdout/stderr, triển khai các hệ thống giám sát mạnh mẽ như Prometheus, và thành thạo các công cụ gỡ lỗi của kubectl, bạn có thể tự tin vận hành và duy trì sự ổn định cho các ứng dụng phức tạp trên Kubernetes. Với những kỹ năng này, bạn không chỉ là một người xây dựng ứng dụng, mà còn là một người "bác sĩ" có khả-năng-chẩn-đoán và "chữa bệnh" cho hệ thống của mình.
Chương 11: Tối Ưu Hóa Quy Trình Phát Triển (Development Workflow)
- Chương 11.1. Vòng lặp phát triển: Code -> Build -> Deploy -> Test.
- Chương 11.2.
Skaffold: Tự động hóa vòng lặp phát triển trên Kubernetes. - Chương 11.3.
Telepresence: Phát triển và debug service cục bộ như thể nó đang chạy trong cluster. - Chương 11.4.
DevSpace: Một lựa chọn mạnh mẽ khác. - Chương 11.5. Xây dựng Docker image hiệu quả cho Kubernetes.
Phần IV: Helm - Trình Quản Lý Gói cho Kubernetes
Chương 12: Giới Thiệu về Helm
- 12.1. Helm là gì và tại sao nó cần thiết?
- 12.2. Các khái niệm cốt lõi: Chart, Release, Repository.
- 12.3. Kiến trúc Helm (Helm 3).
- 12.4. Cài đặt và cấu hình Helm.
Chương 13: Sử Dụng Helm Chart
- 13.1. Tìm kiếm Chart từ các repository (Artifact Hub).
- 13.2. Cài đặt một Chart (
helm install). - 13.3. Tùy chỉnh Chart với file
values.yaml. - 13.4. Quản lý các Release (
helm list,helm status,helm upgrade,helm rollback,helm uninstall).
Chương 14: Xây Dựng Helm Chart của Riêng Bạn
- 14.1. Cấu trúc của một Chart (
Chart.yaml,values.yaml,templates/,charts/). - 14.2. Go Templating Engine: Ngôn ngữ của Helm.
- 14.2.1. Biến, hàm, và pipelines.
- 14.2.2. Các đối tượng tích hợp sẵn (
.Values,.Release,.Chart). - 14.2.3. Luồng điều khiển (if/else, range).
- 14.2.4. Named Templates (
_helpers.tpl).
- 14.3. Quản lý các Chart phụ thuộc (Dependencies).
- 14.4.
helm lintvàhelm template: Debugging Chart của bạn. - 15.5. Đóng gói và chia sẻ Chart (
helm package, Chart Repository).
- 14.1. Cấu trúc của một Chart (
Phần V: Các Chủ Đề Nâng Cao và Mở Rộng
Chương 15: Bảo Mật trong Kubernetes cho Developer
- 15.1.
RBAC(Role-Based Access Control): Ai được làm gì?- 15.1.1.
Role,ClusterRole,RoleBinding,ClusterRoleBinding.
- 15.1.1.
- 15.2.
ServiceAccount: Định danh cho ứng dụng. - 15.3.
PodSecurityPolicy/Pod Security Admission. - 15.4.
NetworkPolicy: Tường lửa cho Pods. - 15.5. Quét lỗ hổng bảo mật trong container image.
- 15.1.
Chương 16: CI/CD với Kubernetes
- 16.1. Tổng quan về CI/CD trong thế giới Kubernetes.
- 16.2. Tích hợp Kubernetes với Jenkins.
- 16.3. Tích hợp Kubernetes với GitLab CI/CD.
- 16.4.
Argo CD: GitOps - "Infrastructure as Code" cho Kubernetes. - 16.5.
Flux CD: Một lựa chọn GitOps phổ biến khác.
Chương 17: Service Mesh - Quản Lý Giao Tiếp Giữa Các Service
- 17.1. Service Mesh là gì?
- 17.2.
Istio: Giới thiệu và kiến trúc. - 17.3.
Linkerd: Đơn giản và hiệu quả. - 17.4. Các tính năng chính: Traffic Management, Observability, Security.
Chương 18: Mở Rộng Kubernetes với Operators và CRDs
- 18.1.
Custom Resource Definitions(CRDs): Mở rộng Kubernetes API. - 18.2.
Operator Pattern: Tự động hóa quản lý ứng dụng phức tạp. - 18.3. Xây dựng một Operator đơn giản với
Operator SDKhoặcKubebuilder.
- 18.1.
Phụ Lục
- A: Bảng thuật ngữ Kubernetes.
- B: Tổng hợp các lệnh
kubectlhữu ích. - C: Các lỗi thường gặp và cách khắc phục.
- D: Tài liệu tham khảo và các khóa học đề xuất.
Phần III: Vận Hành và Tối Ưu Hóa cho Developer
Chương 9: Health Checks và Quản Lý Tài Nguyên
Việc triển khai được một ứng dụng chỉ là bước khởi đầu. Để vận hành một hệ thống đáng tin cậy, chúng ta cần trả lời hai câu hỏi quan trọng:
- Làm sao để biết ứng dụng của chúng ta vẫn đang hoạt động bình thường và sẵn sàng phục vụ người dùng?
- Làm sao để đảm bảo ứng dụng có đủ tài nguyên (CPU, Memory) để chạy, nhưng cũng không chiếm dụng quá mức gây ảnh hưởng đến các ứng dụng khác?
Chương này sẽ đi sâu vào hai cơ chế cốt lõi của Kubernetes giúp giải quyết những vấn đề trên: Health Checks (Probes) và Resource Management (Requests & Limits).
9.1. Liveness Probe: Pod của bạn có còn "sống"?
Vấn đề: Đôi khi, một ứng dụng vẫn đang chạy (tiến trình process vẫn tồn tại) nhưng lại rơi vào trạng thái không thể hoạt động được, ví dụ như bị deadlock, hết bộ nhớ, hoặc một vòng lặp vô hạn. Từ bên ngoài, tiến trình vẫn "sống", nhưng nó không còn khả năng xử lý yêu cầu hay làm bất cứ việc gì hữu ích.
Giải pháp: Liveness Probe (Thăm dò sự sống) là một cơ chế cho phép kubelet kiểm tra xem một container có còn hoạt động đúng cách hay không.
- Nếu Liveness Probe thành công:
kubeletkhông làm gì cả. - Nếu Liveness Probe thất bại:
kubeletsẽ giết (kill) container đó và khởi động lại nó theorestartPolicycủa Pod.
Hành động "giết và khởi động lại" này cực kỳ hiệu quả trong việc tự động phục hồi các ứng dụng bị treo.
Kubernetes cung cấp ba cách để thực hiện một probe:
- HTTP Probe (
httpGet):kubeletgửi một yêu cầu HTTP GET đến một endpoint cụ thể trong container của bạn. Nếu nhận được mã trả về trong khoảng 200-399, probe được coi là thành công. - TCP Probe (
tcpSocket):kubeletcố gắng mở một kết nối TCP đến một port cụ thể trong container. Nếu kết nối thành công, probe được coi là thành công. - Command Probe (
exec):kubeletthực thi một lệnh bên trong container. Nếu lệnh trả về exit code 0, probe được coi là thành công.
Ví dụ về Liveness Probe:
apiVersion: v1
kind: Pod
metadata:
name: liveness-pod
spec:
containers:
- name: my-app
image: my-app-image
livenessProbe:
httpGet:
path: /healthz # Endpoint kiểm tra sức khỏe
port: 8080
initialDelaySeconds: 15 # Chờ 15 giây sau khi container khởi động mới bắt đầu probe
periodSeconds: 20 # Thực hiện probe mỗi 20 giây
timeoutSeconds: 1 # Coi là thất bại nếu không nhận được phản hồi sau 1 giây
failureThreshold: 3 # Coi là thất bại thực sự sau 3 lần probe liên tiếp thất bại9.2. Readiness Probe: Pod đã sẵn sàng nhận request chưa?
Vấn đề: Một ứng dụng có thể đã khởi động (liveness probe thành công) nhưng chưa sẵn sàng để nhận traffic. Ví dụ:
- Một ứng dụng Java cần thời gian để khởi tạo Spring context, nạp dữ liệu vào cache.
- Một ứng dụng cần kết nối đến database và thực hiện các migration ban đầu.
Nếu Service gửi traffic đến Pod ngay khi nó vừa khởi động, người dùng có thể sẽ gặp lỗi.
Giải pháp: Readiness Probe (Thăm dò sự sẵn sàng) được dùng để cho Kubernetes biết khi nào một container đã sẵn sàng để bắt đầu nhận traffic.
- Nếu Readiness Probe thành công:
kubeletsẽ đánh dấu Pod làReady.Servicesẽ bắt đầu đưa Pod này vào danh sách các endpoint hợp lệ và gửi traffic đến nó. - Nếu Readiness Probe thất bại:
kubeletsẽ đánh dấu Pod làNotReady.Servicesẽ xóa Pod này khỏi danh sách endpoint. Traffic sẽ không được gửi đến nó nữa cho đến khi probe thành công trở lại.
Quan trọng là, nếu Readiness Probe thất bại, kubelet sẽ không khởi động lại container. Nó chỉ tạm thời "cách ly" Pod ra khỏi luồng traffic.
Tại sao Readiness Probe lại quan trọng cho Rolling Update? Khi bạn thực hiện một Deployment rolling update, Kubernetes sẽ chỉ coi một Pod mới là "sẵn sàng" khi Readiness Probe của nó thành công. Điều này đảm bảo rằng Pod mới chỉ nhận traffic khi nó đã thực sự sẵn sàng 100%, giúp quá trình cập nhật diễn ra mượt mà không gây lỗi cho người dùng (zero-downtime deployment).
Ví dụ về Readiness Probe: Cấu hình của Readiness Probe hoàn toàn tương tự Liveness Probe.
apiVersion: v1
kind: Pod
metadata:
name: readiness-pod
spec:
containers:
- name: my-app
image: my-app-image
readinessProbe:
httpGet:
path: /ready
port: 8080
initialDelaySeconds: 5
periodSeconds: 10Best Practice: Luôn luôn định nghĩa cả
LivenessvàReadinessprobe.Livenessđể khởi động lại ứng dụng bị treo,Readinessđể đảm bảo cập nhật an toàn và không gửi traffic đến ứng dụng chưa sẵn sàng. Endpoint củaReadinessprobe thường phức tạp hơn, có thể cần kiểm tra cả kết nối đến database, message queue, v.v.
9.3. Startup Probe: Dành cho các ứng dụng khởi động chậm
Vấn đề: Một số ứng dụng (đặc biệt là các ứng dụng Java cũ hoặc các ứng dụng cần thực hiện nhiều tác vụ nặng khi khởi động) có thể mất vài phút để bắt đầu. Nếu initialDelaySeconds của Liveness Probe quá ngắn, kubelet có thể giết chết container trước khi nó kịp khởi động xong, gây ra một vòng lặp khởi động lại không hồi kết (CrashLoopBackOff).
Giải pháp: Startup Probe (Thăm dò khởi động) được thiết kế đặc biệt cho trường hợp này.
- Khi
Startup Probeđược định nghĩa, tất cả các probe khác sẽ bị vô hiệu hóa cho đến khiStartup Probethành công. Startup Probecó một khoảng thời gian dài (failureThreshold*periodSeconds) để hoàn thành.- Nếu Startup Probe thành công:
kubeletsẽ bắt đầu thực hiệnLivenessvàReadinessprobe như bình thường. - Nếu Startup Probe thất bại (vượt quá thời gian cho phép):
kubeletsẽ giết và khởi động lại container.
Ví dụ về Startup Probe:
startupProbe:
httpGet:
path: /healthz
port: 8080
failureThreshold: 30 # Thử lại 30 lần
periodSeconds: 10 # Mỗi lần cách nhau 10 giây
# => Container có tổng cộng 30 * 10 = 300 giây (5 phút) để khởi động.9.4. Requests và Limits: Quản lý CPU và Memory
Trong một cluster chia sẻ, việc quản lý tài nguyên là tối quan trọng. Kubernetes cho phép bạn chỉ định lượng CPU và Memory mà mỗi container cần và được phép sử dụng thông qua hai tham số: requests và limits.
requests (Yêu cầu):
- Ý nghĩa: Lượng tài nguyên được đảm bảo (guaranteed) cho container.
- Cách hoạt động:
- Memory Request: Kubernetes đảm bảo container sẽ luôn có ít nhất lượng memory này.
- CPU Request: Kubernetes đảm bảo container sẽ nhận được phần CPU tương ứng. CPU là tài nguyên có thể "nén" được (compressible), nên nếu có CPU nhàn rỗi, container có thể dùng nhiều hơn mức request.
- Vai trò với Scheduler:
kube-schedulersử dụngrequestsđể quyết định đặt Pod ở đâu. Nó sẽ chỉ đặt Pod lên một Node nếu Node đó có đủ tài nguyên chưa được cấp phát để đáp ứngrequestscủa Pod.
limits (Giới hạn):
- Ý nghĩa: Lượng tài nguyên tối đa mà container được phép sử dụng.
- Cách hoạt động:
- Memory Limit: Nếu container cố gắng sử dụng nhiều memory hơn
limit, nó sẽ bị giết với lỗi OOMKilled (Out of Memory). - CPU Limit: Nếu container cố gắng sử dụng nhiều CPU hơn
limit, nó sẽ bị điều tiết (throttled), tức là hiệu năng sẽ bị giảm xuống để không vượt quá giới hạn. Container sẽ không bị giết.
- Memory Limit: Nếu container cố gắng sử dụng nhiều memory hơn
Đơn vị đo lường:
- Memory:
Ki(Kibibyte),Mi(Mebibyte),Gi(Gibibyte),Ti(Tebibyte). - CPU:
m(millicpu hoặc millicore).1000mtương đương với 1 vCPU/core.500mlà nửa core.
Ví dụ:
resources:
requests:
memory: "64Mi"
cpu: "250m" # 0.25 core
limits:
memory: "128Mi"
cpu: "500m" # 0.5 coreBest Practice: Luôn luôn đặt
requestsvàlimitscho mọi container trong môi trường production. Điều này giúp Scheduler đưa ra quyết định tốt hơn, tránh tình trạng "hàng xóm ồn ào" (một Pod dùng quá nhiều tài nguyên ảnh hưởng đến các Pod khác), và làm cho cluster hoạt động ổn định hơn.
9.5. Quality of Service (QoS) Classes
Dựa trên cách bạn đặt requests và limits, Kubernetes sẽ tự động gán cho Pod của bạn một trong ba lớp Chất lượng Dịch vụ (QoS). Lớp QoS này quyết định Pod nào sẽ bị giết trước tiên khi Node cạn kiệt tài nguyên (đặc biệt là Memory).
Guaranteed(Đảm bảo):- Điều kiện: Mọi container trong Pod phải có cả
memory requestvàmemory limit, và chúng phải bằng nhau. Tương tự cho CPU. - Đặc điểm: Đây là các Pod có độ ưu tiên cao nhất. Chúng sẽ là những Pod cuối cùng bị giết nếu Node hết tài nguyên.
- Ví dụ:yaml
resources: requests: memory: "128Mi" cpu: "500m" limits: memory: "128Mi" cpu: "500m"
- Điều kiện: Mọi container trong Pod phải có cả
Burstable(Có thể bùng nổ):- Điều kiện: Ít nhất một container trong Pod có
requestnhưnglimitlớn hơnrequest, hoặc chỉ córequestmà không cólimit. - Đặc điểm: Các Pod này được phép "bùng nổ" sử dụng nhiều tài nguyên hơn mức request nếu có tài nguyên nhàn rỗi trên Node. Chúng có độ ưu tiên trung bình và sẽ bị giết sau các Pod
BestEffort. - Ví dụ:yaml
resources: requests: memory: "64Mi" cpu: "250m" limits: memory: "128Mi" cpu: "500m"
- Điều kiện: Ít nhất một container trong Pod có
BestEffort(Nỗ lực tốt nhất):- Điều kiện: Không có bất kỳ container nào trong Pod có
requestshoặclimits. - Đặc điểm: Đây là các Pod có độ ưu tiên thấp nhất. Chúng sẽ là những Pod đầu tiên bị giết khi Node hết tài nguyên. Chỉ nên dùng cho các tác vụ có độ ưu tiên thấp, không quan trọng.
- Điều kiện: Không có bất kỳ container nào trong Pod có
9.6. ResourceQuota và LimitRange: Giới hạn tài nguyên ở mức Namespace
Requests và limits được đặt ở cấp độ container. Nhưng làm thế nào để một Admin có thể kiểm soát tổng lượng tài nguyên mà một team hoặc một dự án được phép sử dụng?
ResourceQuota:- Cho phép Admin đặt ra giới hạn tổng tài nguyên cho một
namespace. - Ví dụ: Namespace
team-achỉ được phép yêu cầu tổng cộng 20 core CPU và 64GiB Memory, và chỉ được tạo tối đa 10Service. - Nếu việc tạo một tài nguyên mới (Pod, Service) làm vượt quá quota, yêu cầu sẽ bị từ chối.
- Cho phép Admin đặt ra giới hạn tổng tài nguyên cho một
LimitRange:- Cho phép Admin đặt ra các giới hạn mặc định, giới hạn tối thiểu/tối đa cho các tài nguyên trong một
namespace. - Ví dụ:
- Nếu một Pod được tạo mà không có
requests/limits, nó sẽ tự động được gán giá trị mặc định. - Đảm bảo không ai có thể tạo một Pod yêu cầu quá nhiều tài nguyên (ví dụ: 100GiB Memory).
- Đảm bảo mọi Pod đều có
requesttối thiểu.
- Nếu một Pod được tạo mà không có
- Cho phép Admin đặt ra các giới hạn mặc định, giới hạn tối thiểu/tối đa cho các tài nguyên trong một
Hai công cụ này rất quan trọng cho các môi trường đa người dùng (multi-tenant), giúp đảm bảo sự công bằng và ổn định cho toàn bộ cluster.
Kết luận Chương 9: Việc cấu hình Health Checks và Resource Management là một bước chuyển từ "chạy được" sang "chạy tốt và đáng tin cậy". Liveness, Readiness, và Startup probes là những người bảo vệ thầm lặng, đảm bảo ứng dụng của bạn luôn khỏe mạnh và các bản cập nhật diễn ra an toàn. Requests và Limits là nền tảng của sự ổn định và khả năng dự đoán trong một môi trường chia sẻ tài nguyên. Nắm vững các khái niệm này, bạn đã tiến một bước dài trên con đường trở thành một kỹ sư vận hành ứng dụng chuyên nghiệp trên Kubernetes. Tiếp theo, chúng ta sẽ khám phá bộ công cụ cần thiết để "nhìn" vào bên trong hệ thống: Logging, Monitoring và Debugging.
Chương 10: Logging, Monitoring và Debugging
Chúng ta đã học cách triển khai, kết nối, cấu hình và quản lý tài nguyên cho ứng dụng. Nhưng khi hệ thống đã chạy, làm thế nào chúng ta biết được điều gì đang thực sự xảy ra bên trong? Khi có lỗi, làm thế nào để tìm ra nguyên nhân? Đây là lúc bộ ba "thần thánh" của vận hành hệ thống vào cuộc: Logging (Ghi log), Monitoring (Giám sát), và Debugging (Gỡ lỗi).
Trong một hệ thống phân tán và năng động như Kubernetes, việc "quan sát" (Observability) không còn là một tùy chọn, mà là một yêu cầu bắt buộc.
10.1. Logging
Logging là việc ghi lại các sự kiện rời rạc, theo thời gian đã xảy ra trong ứng dụng. Mỗi dòng log là một "dấu vết" về một hành động hoặc một sự kiện cụ thể.
10.1.1. Triết lý Logging trong Kubernetes: Ghi log ra stdout và stderr
Trong môi trường container, cách tiếp cận tốt nhất và đơn giản nhất là để ứng dụng của bạn ghi log trực tiếp ra hai luồng (stream) tiêu chuẩn: standard output (stdout) cho các log thông thường và standard error (stderr) cho các log lỗi.
Tại sao lại như vậy?
- Tách biệt mối quan tâm: Ứng dụng của bạn chỉ cần tập trung vào việc tạo ra log. Nó không cần quan tâm đến việc log sẽ được lưu trữ ở đâu, xoay vòng (rotate) như thế nào, hay gửi đi đâu. Việc định tuyến và xử lý log là nhiệm vụ của hạ tầng.
- Tính di động: Ứng dụng của bạn không bị phụ thuộc vào một hệ thống file cụ thể. Nó có thể chạy ở bất cứ đâu.
- Tích hợp tự nhiên: Container runtime (như
containerd) vàkubeletđược thiết kế để tự động thu thập các luồngstdoutvàstderrnày.
Khi bạn chạy lệnh kubectl logs <tên-pod>, bạn đang thực chất đọc lại các bản ghi mà kubelet đã thu thập từ stdout và stderr của container.
10.1.2. Kiến trúc logging trong Kubernetes
Việc dùng kubectl logs chỉ phù hợp để xem log nhanh của một Pod. Khi Pod bị xóa, log của nó cũng biến mất. Để có một hệ thống logging bền bỉ và tập trung, chúng ta cần một giải pháp ở cấp độ cluster. Có hai kiến trúc chính:
1. Node-level Logging Agent (Agent ghi log ở cấp độ Node): Đây là kiến trúc phổ biến và được khuyến khích nhất.
- Cách hoạt động: Một agent chuyên dụng (như
Fluentd,Promtail,Vector) được triển khai trên mỗi Worker Node dưới dạng mộtDaemonSet. - Agent này sẽ tự động truy cập vào các file log mà
kubelettạo ra trên Node (thường ở/var/log/pods/...). - Nó sẽ đọc, xử lý (ví dụ: thêm metadata như tên Pod, namespace), và gửi log đến một backend lưu trữ tập trung (như Elasticsearch, Loki, hoặc một dịch vụ cloud).
- Ưu điểm: Hiệu quả, tự động thu thập log từ tất cả các Pod trên Node mà không cần thay đổi ứng dụng.
2. Sidecar Logging Container: Kiến trúc này được sử dụng trong các trường hợp đặc biệt.
- Cách hoạt động: Một container "sidecar" được thêm vào mỗi Pod của ứng dụng.
- Ứng dụng chính có thể ghi log vào một file trong một
Volumedùng chung, hoặc sidecar có thể "đuôi" (tail)stdout/stderrcủa ứng dụng chính. - Container sidecar sau đó sẽ chịu trách nhiệm gửi log đến backend tập trung.
- Trường hợp sử dụng:
- Khi ứng dụng không thể dễ dàng sửa đổi để ghi ra
stdout/stderr(ví dụ: một ứng dụng cũ ghi vào file cố định). - Khi bạn cần xử lý log một cách chuyên biệt cho từng ứng dụng.
- Khi ứng dụng không thể dễ dàng sửa đổi để ghi ra
- Nhược điểm: Tốn nhiều tài nguyên hơn (mỗi Pod có thêm một container), phức tạp hơn để cấu hình.
10.1.3. Bộ công cụ EFK/Loki-Promtail
EFK Stack (Elasticsearch, Fluentd, Kibana):
- Fluentd: Agent (
DaemonSet) thu thập, xử lý và gửi log. - Elasticsearch: Một công cụ tìm kiếm và phân tích mạnh mẽ, dùng để lưu trữ và đánh chỉ mục (index) log.
- Kibana: Giao diện web để tìm kiếm, trực quan hóa và phân tích log trong Elasticsearch.
- Đây là một bộ công cụ rất mạnh mẽ nhưng cũng khá phức tạp và tốn tài nguyên (đặc biệt là Elasticsearch).
- Fluentd: Agent (
Loki, Promtail, và Grafana:
- Promtail: Một agent cực kỳ nhẹ (
DaemonSet) được thiết kế chuyên biệt để thu thập log và gửi cho Loki. - Loki: Backend lưu trữ log, được phát triển bởi Grafana Labs. Triết lý của Loki là "chỉ đánh chỉ mục metadata, không phải nội dung log". Nó chỉ index các
label(giống Prometheus) nhưpod,namespace,app. Điều này giúp Loki cực kỳ hiệu quả về chi phí lưu trữ và tài nguyên so với Elasticsearch. - Grafana: Giao diện để truy vấn (bằng ngôn ngữ LogQL) và hiển thị log từ Loki, cũng như metrics từ Prometheus, tạo ra một nền tảng quan sát hợp nhất.
- Bộ công cụ này đang ngày càng trở nên phổ biến vì sự đơn giản và hiệu quả của nó.
- Promtail: Một agent cực kỳ nhẹ (
10.2. Monitoring
Nếu logging cho chúng ta biết "điều gì đã xảy ra", thì monitoring cho chúng ta biết "hệ thống đang hoạt động như thế nào" ở một góc độ tổng hợp. Monitoring tập trung vào việc thu thập, xử lý và hiển thị các chỉ số (metrics) dạng số theo thời gian.
10.2.1. Các chỉ số quan trọng cần theo dõi
Có hai phương pháp luận phổ biến để xác định những gì cần theo dõi:
- The RED Method (Rate, Errors, Duration): Dành cho các hệ thống dựa trên request.
- Rate: Số lượng request mỗi giây.
- Errors: Số lượng request thất bại mỗi giây.
- Duration: Thời gian xử lý mỗi request (thường là phân vị 95, 99).
- The USE Method (Utilization, Saturation, Errors): Dành cho việc theo dõi tài nguyên.
- Utilization: Mức độ sử dụng tài nguyên (ví dụ: CPU đang sử dụng 80%).
- Saturation: Mức độ "bận rộn" của tài nguyên, thường biểu thị qua hàng đợi (ví dụ: CPU load average).
- Errors: Số lượng lỗi của tài nguyên (ví dụ: lỗi mạng, lỗi ổ đĩa).
10.2.2. Kiến trúc Metrics trong Kubernetes
cAdvisor: Một thành phần được tích hợp sẵn trongkubelet. Nó tự động thu thập các metrics cơ bản về hiệu suất của container và Node (sử dụng CPU, memory, network, file system).Metrics Server: Một thành phần cluster-level, thu thập dữ liệu từ tất cả cáccAdvisorvà tổng hợp chúng lại. Nó cung cấp một API tối giản (metrics.k8s.io) cho phép bạn xem mức sử dụng tài nguyên hiện tại. Đây là nguồn dữ liệu cho các lệnh nhưkubectl top podvàkubectl top node.Metrics Serverkhông lưu trữ dữ liệu lịch sử.- Hệ thống Monitoring đầy đủ (Prometheus): Để có thể giám sát một cách toàn diện, lưu trữ dữ liệu lịch sử và thiết lập cảnh báo, bạn cần một giải pháp như Prometheus.
10.2.3. Prometheus và Grafana: Tiêu chuẩn vàng của monitoring
Prometheus:
- Là một dự án tốt nghiệp của CNCF và là tiêu chuẩn de facto cho monitoring trong hệ sinh thái cloud-native.
- Mô hình Pull-based: Prometheus Server định kỳ "kéo" (scrape) metrics từ các endpoint HTTP (
/metrics) mà các ứng dụng hoặc các "exporter" phơi bày ra. - Service Discovery: Prometheus tích hợp hoàn hảo với Kubernetes. Nó có thể tự động phát hiện tất cả các Pod, Service, Node trong cluster và tìm ra các endpoint
/metricsđể scrape. - PromQL: Một ngôn ngữ truy vấn cực kỳ mạnh mẽ và linh hoạt để bạn có thể tổng hợp, tính toán và phân tích dữ liệu time-series.
- Alertmanager: Một thành phần đi kèm để xử lý việc gửi cảnh báo (alert) qua email, Slack, PagerDuty, v.v.
Grafana:
- Là công cụ trực quan hóa hàng đầu cho dữ liệu time-series.
- Nó có thể kết nối với Prometheus (và nhiều nguồn dữ liệu khác) để tạo ra các dashboard đẹp mắt, tương tác, giúp bạn dễ dàng theo dõi sức khỏe của hệ thống.
10.3. Debugging
Khi logging và monitoring cho thấy có vấn đề, bạn cần các công cụ để "lặn sâu" vào hệ thống và tìm ra gốc rễ của vấn đề.
10.3.1. Bộ tứ kubectl cho Debugging
kubectl logs: Luôn là điểm bắt đầu. Xem log của Pod để tìm các thông báo lỗi hoặc stack trace.kubectl logs <pod-name>kubectl logs -f <pod-name>(theo dõi log)kubectl logs --previous <pod-name>(xem log của container đã bị khởi động lại)
kubectl describe pod <pod-name>: Cung cấp một "bản tóm tắt" toàn diện về Pod. Hãy đặc biệt chú ý đến phần Events ở cuối cùng. Phần này ghi lại các sự kiện quan trọng trong vòng đời của Pod, ví dụ như "Failed to pull image", "Liveness probe failed", "Node is out of memory". Rất nhiều vấn đề có thể được chẩn đoán chỉ bằng cách đọc Events.kubectl get events --sort-by='.lastTimestamp': Xem danh sách tất cả các sự kiện gần đây trong namespace, giúp bạn có một cái nhìn tổng quan về những gì đang xảy ra.kubectl exec -it <pod-name> -- /bin/bash: "Nhảy" vào bên trong một container đang chạy. Đây là công cụ cực kỳ mạnh mẽ để:- Kiểm tra xem các file cấu hình đã được mount đúng chưa (
ls,cat). - Kiểm tra kết nối mạng từ bên trong Pod (
ping,curl,netstat). - Kiểm tra các biến môi trường (
env).
- Kiểm tra xem các file cấu hình đã được mount đúng chưa (
10.3.2. Debugging các lỗi Pod phổ biến
Pending: Pod bị kẹt ở trạng tháiPending. Dùngkubectl describeđể xem lý do.- Lý do phổ biến: Cluster không đủ tài nguyên (CPU/Memory) để đáp ứng
requestscủa Pod; Pod yêu cầu mộtVolumekhông tồn tại hoặc không có sẵn;taints/tolerationskhông khớp.
- Lý do phổ biến: Cluster không đủ tài nguyên (CPU/Memory) để đáp ứng
ImagePullBackOff/ErrImagePull:kubeletkhông thể kéo container image.- Lý do phổ biến: Sai tên image hoặc tag; image không tồn tại; cần thông tin xác thực để kéo image từ private registry nhưng
Secret(loạidockerconfigjson) chưa được cung cấp.
- Lý do phổ biến: Sai tên image hoặc tag; image không tồn tại; cần thông tin xác thực để kéo image từ private registry nhưng
CrashLoopBackOff: Container khởi động, bị crash, rồikubeletlại cố gắng khởi động lại nó, tạo thành một vòng lặp.- Đây là một triệu chứng, không phải nguyên nhân. Nguyên nhân thực sự là do ứng dụng của bạn bị crash ngay khi khởi động.
- Cách debug: Dùng
kubectl logs --previous <pod-name>để xem log của lần chạy trước khi nó bị crash. Rất có thể bạn sẽ thấy một lỗi nghiêm trọng (panic, unhandled exception) ở đó.
OOMKilled: Container đã cố gắng sử dụng nhiều Memory hơn mứclimitcủa nó và đã bịkubeletgiết.- Cách debug: Tăng
memory limithoặc tối ưu hóa việc sử dụng memory của ứng dụng.
- Cách debug: Tăng
10.3.3. Ephemeral Containers: Debugging live
Đôi khi, bạn cần debug một Pod đang chạy nhưng image của nó lại không chứa các công cụ cần thiết (như curl, net-tools). Việc exec vào và cài đặt chúng sẽ làm thay đổi container.
Ephemeral Containers (tính năng ổn định từ Kubernetes 1.25) cho phép bạn "gắn" một container gỡ lỗi tạm thời vào một Pod đang chạy mà không cần khởi động lại nó.
# Gắn một container tên 'debugger' dùng image 'busybox' vào pod 'my-pod'
kubectl debug -it my-pod --image=busybox --target=my-app-containerLệnh này sẽ tạo một container mới trong Pod, chia sẻ chung network và process namespace với container my-app-container, cho phép bạn sử dụng các công cụ từ busybox để kiểm tra môi trường của container chính.
10.3.4. kubectl port-forward: Truy cập ứng dụng trực tiếp
Khi bạn muốn truy cập trực tiếp vào một port của Pod từ máy local của mình để test hoặc debug (ví dụ: kết nối một debugger từ IDE, truy cập vào một web UI nội bộ), port-forward là công cụ dành cho bạn.
# Chuyển tiếp port 8080 trên máy local đến port 80 của pod 'my-web-pod'
kubectl port-forward my-web-pod 8080:80Bây giờ, bạn có thể mở trình duyệt và truy cập http://localhost:8080, traffic sẽ được chuyển tiếp an toàn đến Pod trong cluster.
Kết luận Chương 10: Logging, Monitoring, và Debugging là ba trụ cột của khả năng quan sát hệ thống. Bằng cách áp dụng triết lý ghi log ra stdout/stderr, triển khai các hệ thống giám sát mạnh mẽ như Prometheus, và thành thạo các công cụ gỡ lỗi của kubectl, bạn có thể tự tin vận hành và duy trì sự ổn định cho các ứng dụng phức tạp trên Kubernetes. Với những kỹ năng này, bạn không chỉ là một người xây dựng ứng dụng, mà còn là một người "bác sĩ" có khả-năng-chẩn-đoán và "chữa bệnh" cho hệ thống của mình.
Chương 11: Tối Ưu Hóa Quy Trình Phát Triển (Development Workflow)
- Chương 11.1. Vòng lặp phát triển: Code -> Build -> Deploy -> Test.
- Chương 11.2.
Skaffold: Tự động hóa vòng lặp phát triển trên Kubernetes. - Chương 11.3.
Telepresence: Phát triển và debug service cục bộ như thể nó đang chạy trong cluster. - Chương 11.4.
DevSpace: Một lựa chọn mạnh mẽ khác. - Chương 11.5. Xây dựng Docker image hiệu quả cho Kubernetes.
Phần IV: Helm - Trình Quản Lý Gói cho Kubernetes
Chương 12: Giới Thiệu về Helm
- 12.1. Helm là gì và tại sao nó cần thiết?
- 12.2. Các khái niệm cốt lõi: Chart, Release, Repository.
- 12.3. Kiến trúc Helm (Helm 3).
- 12.4. Cài đặt và cấu hình Helm.
Chương 13: Sử Dụng Helm Chart
- 13.1. Tìm kiếm Chart từ các repository (Artifact Hub).
- 13.2. Cài đặt một Chart (
helm install). - 13.3. Tùy chỉnh Chart với file
values.yaml. - 13.4. Quản lý các Release (
helm list,helm status,helm upgrade,helm rollback,helm uninstall).
Chương 14: Xây Dựng Helm Chart của Riêng Bạn
- 14.1. Cấu trúc của một Chart (
Chart.yaml,values.yaml,templates/,charts/). - 14.2. Go Templating Engine: Ngôn ngữ của Helm.
- 14.2.1. Biến, hàm, và pipelines.
- 14.2.2. Các đối tượng tích hợp sẵn (
.Values,.Release,.Chart). - 14.2.3. Luồng điều khiển (if/else, range).
- 14.2.4. Named Templates (
_helpers.tpl).
- 14.3. Quản lý các Chart phụ thuộc (Dependencies).
- 14.4.
helm lintvàhelm template: Debugging Chart của bạn. - 15.5. Đóng gói và chia sẻ Chart (
helm package, Chart Repository).
- 14.1. Cấu trúc của một Chart (
Phần V: Các Chủ Đề Nâng Cao và Mở Rộng
Chương 15: Bảo Mật trong Kubernetes cho Developer
- 15.1.
RBAC(Role-Based Access Control): Ai được làm gì?- 15.1.1.
Role,ClusterRole,RoleBinding,ClusterRoleBinding.
- 15.1.1.
- 15.2.
ServiceAccount: Định danh cho ứng dụng. - 15.3.
PodSecurityPolicy/Pod Security Admission. - 15.4.
NetworkPolicy: Tường lửa cho Pods. - 15.5. Quét lỗ hổng bảo mật trong container image.
- 15.1.
Chương 16: CI/CD với Kubernetes
- 16.1. Tổng quan về CI/CD trong thế giới Kubernetes.
- 16.2. Tích hợp Kubernetes với Jenkins.
- 16.3. Tích hợp Kubernetes với GitLab CI/CD.
- 16.4.
Argo CD: GitOps - "Infrastructure as Code" cho Kubernetes. - 16.5.
Flux CD: Một lựa chọn GitOps phổ biến khác.
Chương 17: Service Mesh - Quản Lý Giao Tiếp Giữa Các Service
- 17.1. Service Mesh là gì?
- 17.2.
Istio: Giới thiệu và kiến trúc. - 17.3.
Linkerd: Đơn giản và hiệu quả. - 17.4. Các tính năng chính: Traffic Management, Observability, Security.
Chương 18: Mở Rộng Kubernetes với Operators và CRDs
- 18.1.
Custom Resource Definitions(CRDs): Mở rộng Kubernetes API. - 18.2.
Operator Pattern: Tự động hóa quản lý ứng dụng phức tạp. - 18.3. Xây dựng một Operator đơn giản với
Operator SDKhoặcKubebuilder.
- 18.1.
Phụ Lục
- A: Bảng thuật ngữ Kubernetes.
- B: Tổng hợp các lệnh
kubectlhữu ích. - C: Các lỗi thường gặp và cách khắc phục.
- D: Tài liệu tham khảo và các khóa học đề xuất.
Phần III: Vận Hành và Tối Ưu Hóa cho Developer
Chương 9: Health Checks và Quản Lý Tài Nguyên
Việc triển khai được một ứng dụng chỉ là bước khởi đầu. Để vận hành một hệ thống đáng tin cậy, chúng ta cần trả lời hai câu hỏi quan trọng:
- Làm sao để biết ứng dụng của chúng ta vẫn đang hoạt động bình thường và sẵn sàng phục vụ người dùng?
- Làm sao để đảm bảo ứng dụng có đủ tài nguyên (CPU, Memory) để chạy, nhưng cũng không chiếm dụng quá mức gây ảnh hưởng đến các ứng dụng khác?
Chương này sẽ đi sâu vào hai cơ chế cốt lõi của Kubernetes giúp giải quyết những vấn đề trên: Health Checks (Probes) và Resource Management (Requests & Limits).
9.1. Liveness Probe: Pod của bạn có còn "sống"?
Vấn đề: Đôi khi, một ứng dụng vẫn đang chạy (tiến trình process vẫn tồn tại) nhưng lại rơi vào trạng thái không thể hoạt động được, ví dụ như bị deadlock, hết bộ nhớ, hoặc một vòng lặp vô hạn. Từ bên ngoài, tiến trình vẫn "sống", nhưng nó không còn khả năng xử lý yêu cầu hay làm bất cứ việc gì hữu ích.
Giải pháp: Liveness Probe (Thăm dò sự sống) là một cơ chế cho phép kubelet kiểm tra xem một container có còn hoạt động đúng cách hay không.
- Nếu Liveness Probe thành công:
kubeletkhông làm gì cả. - Nếu Liveness Probe thất bại:
kubeletsẽ giết (kill) container đó và khởi động lại nó theorestartPolicycủa Pod.
Hành động "giết và khởi động lại" này cực kỳ hiệu quả trong việc tự động phục hồi các ứng dụng bị treo.
Kubernetes cung cấp ba cách để thực hiện một probe:
- HTTP Probe (
httpGet):kubeletgửi một yêu cầu HTTP GET đến một endpoint cụ thể trong container của bạn. Nếu nhận được mã trả về trong khoảng 200-399, probe được coi là thành công. - TCP Probe (
tcpSocket):kubeletcố gắng mở một kết nối TCP đến một port cụ thể trong container. Nếu kết nối thành công, probe được coi là thành công. - Command Probe (
exec):kubeletthực thi một lệnh bên trong container. Nếu lệnh trả về exit code 0, probe được coi là thành công.
Ví dụ về Liveness Probe:
apiVersion: v1
kind: Pod
metadata:
name: liveness-pod
spec:
containers:
- name: my-app
image: my-app-image
livenessProbe:
httpGet:
path: /healthz # Endpoint kiểm tra sức khỏe
port: 8080
initialDelaySeconds: 15 # Chờ 15 giây sau khi container khởi động mới bắt đầu probe
periodSeconds: 20 # Thực hiện probe mỗi 20 giây
timeoutSeconds: 1 # Coi là thất bại nếu không nhận được phản hồi sau 1 giây
failureThreshold: 3 # Coi là thất bại thực sự sau 3 lần probe liên tiếp thất bại9.2. Readiness Probe: Pod đã sẵn sàng nhận request chưa?
Vấn đề: Một ứng dụng có thể đã khởi động (liveness probe thành công) nhưng chưa sẵn sàng để nhận traffic. Ví dụ:
- Một ứng dụng Java cần thời gian để khởi tạo Spring context, nạp dữ liệu vào cache.
- Một ứng dụng cần kết nối đến database và thực hiện các migration ban đầu.
Nếu Service gửi traffic đến Pod ngay khi nó vừa khởi động, người dùng có thể sẽ gặp lỗi.
Giải pháp: Readiness Probe (Thăm dò sự sẵn sàng) được dùng để cho Kubernetes biết khi nào một container đã sẵn sàng để bắt đầu nhận traffic.
- Nếu Readiness Probe thành công:
kubeletsẽ đánh dấu Pod làReady.Servicesẽ bắt đầu đưa Pod này vào danh sách các endpoint hợp lệ và gửi traffic đến nó. - Nếu Readiness Probe thất bại:
kubeletsẽ đánh dấu Pod làNotReady.Servicesẽ xóa Pod này khỏi danh sách endpoint. Traffic sẽ không được gửi đến nó nữa cho đến khi probe thành công trở lại.
Quan trọng là, nếu Readiness Probe thất bại, kubelet sẽ không khởi động lại container. Nó chỉ tạm thời "cách ly" Pod ra khỏi luồng traffic.
Tại sao Readiness Probe lại quan trọng cho Rolling Update? Khi bạn thực hiện một Deployment rolling update, Kubernetes sẽ chỉ coi một Pod mới là "sẵn sàng" khi Readiness Probe của nó thành công. Điều này đảm bảo rằng Pod mới chỉ nhận traffic khi nó đã thực sự sẵn sàng 100%, giúp quá trình cập nhật diễn ra mượt mà không gây lỗi cho người dùng (zero-downtime deployment).
Ví dụ về Readiness Probe: Cấu hình của Readiness Probe hoàn toàn tương tự Liveness Probe.
apiVersion: v1
kind: Pod
metadata:
name: readiness-pod
spec:
containers:
- name: my-app
image: my-app-image
readinessProbe:
httpGet:
path: /ready
port: 8080
initialDelaySeconds: 5
periodSeconds: 10Best Practice: Luôn luôn định nghĩa cả
LivenessvàReadinessprobe.Livenessđể khởi động lại ứng dụng bị treo,Readinessđể đảm bảo cập nhật an toàn và không gửi traffic đến ứng dụng chưa sẵn sàng. Endpoint củaReadinessprobe thường phức tạp hơn, có thể cần kiểm tra cả kết nối đến database, message queue, v.v.
9.3. Startup Probe: Dành cho các ứng dụng khởi động chậm
Vấn đề: Một số ứng dụng (đặc biệt là các ứng dụng Java cũ hoặc các ứng dụng cần thực hiện nhiều tác vụ nặng khi khởi động) có thể mất vài phút để bắt đầu. Nếu initialDelaySeconds của Liveness Probe quá ngắn, kubelet có thể giết chết container trước khi nó kịp khởi động xong, gây ra một vòng lặp khởi động lại không hồi kết (CrashLoopBackOff).
Giải pháp: Startup Probe (Thăm dò khởi động) được thiết kế đặc biệt cho trường hợp này.
- Khi
Startup Probeđược định nghĩa, tất cả các probe khác sẽ bị vô hiệu hóa cho đến khiStartup Probethành công. Startup Probecó một khoảng thời gian dài (failureThreshold*periodSeconds) để hoàn thành.- Nếu Startup Probe thành công:
kubeletsẽ bắt đầu thực hiệnLivenessvàReadinessprobe như bình thường. - Nếu Startup Probe thất bại (vượt quá thời gian cho phép):
kubeletsẽ giết và khởi động lại container.
Ví dụ về Startup Probe:
startupProbe:
httpGet:
path: /healthz
port: 8080
failureThreshold: 30 # Thử lại 30 lần
periodSeconds: 10 # Mỗi lần cách nhau 10 giây
# => Container có tổng cộng 30 * 10 = 300 giây (5 phút) để khởi động.9.4. Requests và Limits: Quản lý CPU và Memory
Trong một cluster chia sẻ, việc quản lý tài nguyên là tối quan trọng. Kubernetes cho phép bạn chỉ định lượng CPU và Memory mà mỗi container cần và được phép sử dụng thông qua hai tham số: requests và limits.
requests (Yêu cầu):
- Ý nghĩa: Lượng tài nguyên được đảm bảo (guaranteed) cho container.
- Cách hoạt động:
- Memory Request: Kubernetes đảm bảo container sẽ luôn có ít nhất lượng memory này.
- CPU Request: Kubernetes đảm bảo container sẽ nhận được phần CPU tương ứng. CPU là tài nguyên có thể "nén" được (compressible), nên nếu có CPU nhàn rỗi, container có thể dùng nhiều hơn mức request.
- Vai trò với Scheduler:
kube-schedulersử dụngrequestsđể quyết định đặt Pod ở đâu. Nó sẽ chỉ đặt Pod lên một Node nếu Node đó có đủ tài nguyên chưa được cấp phát để đáp ứngrequestscủa Pod.
limits (Giới hạn):
- Ý nghĩa: Lượng tài nguyên tối đa mà container được phép sử dụng.
- Cách hoạt động:
- Memory Limit: Nếu container cố gắng sử dụng nhiều memory hơn
limit, nó sẽ bị giết với lỗi OOMKilled (Out of Memory). - CPU Limit: Nếu container cố gắng sử dụng nhiều CPU hơn
limit, nó sẽ bị điều tiết (throttled), tức là hiệu năng sẽ bị giảm xuống để không vượt quá giới hạn. Container sẽ không bị giết.
- Memory Limit: Nếu container cố gắng sử dụng nhiều memory hơn
Đơn vị đo lường:
- Memory:
Ki(Kibibyte),Mi(Mebibyte),Gi(Gibibyte),Ti(Tebibyte). - CPU:
m(millicpu hoặc millicore).1000mtương đương với 1 vCPU/core.500mlà nửa core.
Ví dụ:
resources:
requests:
memory: "64Mi"
cpu: "250m" # 0.25 core
limits:
memory: "128Mi"
cpu: "500m" # 0.5 coreBest Practice: Luôn luôn đặt
requestsvàlimitscho mọi container trong môi trường production. Điều này giúp Scheduler đưa ra quyết định tốt hơn, tránh tình trạng "hàng xóm ồn ào" (một Pod dùng quá nhiều tài nguyên ảnh hưởng đến các Pod khác), và làm cho cluster hoạt động ổn định hơn.
9.5. Quality of Service (QoS) Classes
Dựa trên cách bạn đặt requests và limits, Kubernetes sẽ tự động gán cho Pod của bạn một trong ba lớp Chất lượng Dịch vụ (QoS). Lớp QoS này quyết định Pod nào sẽ bị giết trước tiên khi Node cạn kiệt tài nguyên (đặc biệt là Memory).
Guaranteed(Đảm bảo):- Điều kiện: Mọi container trong Pod phải có cả
memory requestvàmemory limit, và chúng phải bằng nhau. Tương tự cho CPU. - Đặc điểm: Đây là các Pod có độ ưu tiên cao nhất. Chúng sẽ là những Pod cuối cùng bị giết nếu Node hết tài nguyên.
- Ví dụ:yaml
resources: requests: memory: "128Mi" cpu: "500m" limits: memory: "128Mi" cpu: "500m"
- Điều kiện: Mọi container trong Pod phải có cả
Burstable(Có thể bùng nổ):- Điều kiện: Ít nhất một container trong Pod có
requestnhưnglimitlớn hơnrequest, hoặc chỉ córequestmà không cólimit. - Đặc điểm: Các Pod này được phép "bùng nổ" sử dụng nhiều tài nguyên hơn mức request nếu có tài nguyên nhàn rỗi trên Node. Chúng có độ ưu tiên trung bình và sẽ bị giết sau các Pod
BestEffort. - Ví dụ:yaml
resources: requests: memory: "64Mi" cpu: "250m" limits: memory: "128Mi" cpu: "500m"
- Điều kiện: Ít nhất một container trong Pod có
BestEffort(Nỗ lực tốt nhất):- Điều kiện: Không có bất kỳ container nào trong Pod có
requestshoặclimits. - Đặc điểm: Đây là các Pod có độ ưu tiên thấp nhất. Chúng sẽ là những Pod đầu tiên bị giết khi Node hết tài nguyên. Chỉ nên dùng cho các tác vụ có độ ưu tiên thấp, không quan trọng.
- Điều kiện: Không có bất kỳ container nào trong Pod có
9.6. ResourceQuota và LimitRange: Giới hạn tài nguyên ở mức Namespace
Requests và limits được đặt ở cấp độ container. Nhưng làm thế nào để một Admin có thể kiểm soát tổng lượng tài nguyên mà một team hoặc một dự án được phép sử dụng?
ResourceQuota:- Cho phép Admin đặt ra giới hạn tổng tài nguyên cho một
namespace. - Ví dụ: Namespace
team-achỉ được phép yêu cầu tổng cộng 20 core CPU và 64GiB Memory, và chỉ được tạo tối đa 10Service. - Nếu việc tạo một tài nguyên mới (Pod, Service) làm vượt quá quota, yêu cầu sẽ bị từ chối.
- Cho phép Admin đặt ra giới hạn tổng tài nguyên cho một
LimitRange:- Cho phép Admin đặt ra các giới hạn mặc định, giới hạn tối thiểu/tối đa cho các tài nguyên trong một
namespace. - Ví dụ:
- Nếu một Pod được tạo mà không có
requests/limits, nó sẽ tự động được gán giá trị mặc định. - Đảm bảo không ai có thể tạo một Pod yêu cầu quá nhiều tài nguyên (ví dụ: 100GiB Memory).
- Đảm bảo mọi Pod đều có
requesttối thiểu.
- Nếu một Pod được tạo mà không có
- Cho phép Admin đặt ra các giới hạn mặc định, giới hạn tối thiểu/tối đa cho các tài nguyên trong một
Hai công cụ này rất quan trọng cho các môi trường đa người dùng (multi-tenant), giúp đảm bảo sự công bằng và ổn định cho toàn bộ cluster.
Kết luận Chương 9: Việc cấu hình Health Checks và Resource Management là một bước chuyển từ "chạy được" sang "chạy tốt và đáng tin cậy". Liveness, Readiness, và Startup probes là những người bảo vệ thầm lặng, đảm bảo ứng dụng của bạn luôn khỏe mạnh và các bản cập nhật diễn ra an toàn. Requests và Limits là nền tảng của sự ổn định và khả năng dự đoán trong một môi trường chia sẻ tài nguyên. Nắm vững các khái niệm này, bạn đã tiến một bước dài trên con đường trở thành một kỹ sư vận hành ứng dụng chuyên nghiệp trên Kubernetes. Tiếp theo, chúng ta sẽ khám phá bộ công cụ cần thiết để "nhìn" vào bên trong hệ thống: Logging, Monitoring và Debugging.
Chương 10: Logging, Monitoring và Debugging
Chúng ta đã học cách triển khai, kết nối, cấu hình và quản lý tài nguyên cho ứng dụng. Nhưng khi hệ thống đã chạy, làm thế nào chúng ta biết được điều gì đang thực sự xảy ra bên trong? Khi có lỗi, làm thế nào để tìm ra nguyên nhân? Đây là lúc bộ ba "thần thánh" của vận hành hệ thống vào cuộc: Logging (Ghi log), Monitoring (Giám sát), và Debugging (Gỡ lỗi).
Trong một hệ thống phân tán và năng động như Kubernetes, việc "quan sát" (Observability) không còn là một tùy chọn, mà là một yêu cầu bắt buộc.
10.1. Logging
Logging là việc ghi lại các sự kiện rời rạc, theo thời gian đã xảy ra trong ứng dụng. Mỗi dòng log là một "dấu vết" về một hành động hoặc một sự kiện cụ thể.
10.1.1. Triết lý Logging trong Kubernetes: Ghi log ra stdout và stderr
Trong môi trường container, cách tiếp cận tốt nhất và đơn giản nhất là để ứng dụng của bạn ghi log trực tiếp ra hai luồng (stream) tiêu chuẩn: standard output (stdout) cho các log thông thường và standard error (stderr) cho các log lỗi.
Tại sao lại như vậy?
- Tách biệt mối quan tâm: Ứng dụng của bạn chỉ cần tập trung vào việc tạo ra log. Nó không cần quan tâm đến việc log sẽ được lưu trữ ở đâu, xoay vòng (rotate) như thế nào, hay gửi đi đâu. Việc định tuyến và xử lý log là nhiệm vụ của hạ tầng.
- Tính di động: Ứng dụng của bạn không bị phụ thuộc vào một hệ thống file cụ thể. Nó có thể chạy ở bất cứ đâu.
- Tích hợp tự nhiên: Container runtime (như
containerd) vàkubeletđược thiết kế để tự động thu thập các luồngstdoutvàstderrnày.
Khi bạn chạy lệnh kubectl logs <tên-pod>, bạn đang thực chất đọc lại các bản ghi mà kubelet đã thu thập từ stdout và stderr của container.
10.1.2. Kiến trúc logging trong Kubernetes
Việc dùng kubectl logs chỉ phù hợp để xem log nhanh của một Pod. Khi Pod bị xóa, log của nó cũng biến mất. Để có một hệ thống logging bền bỉ và tập trung, chúng ta cần một giải pháp ở cấp độ cluster. Có hai kiến trúc chính:
1. Node-level Logging Agent (Agent ghi log ở cấp độ Node): Đây là kiến trúc phổ biến và được khuyến khích nhất.
- Cách hoạt động: Một agent chuyên dụng (như
Fluentd,Promtail,Vector) được triển khai trên mỗi Worker Node dưới dạng mộtDaemonSet. - Agent này sẽ tự động truy cập vào các file log mà
kubelettạo ra trên Node (thường ở/var/log/pods/...). - Nó sẽ đọc, xử lý (ví dụ: thêm metadata như tên Pod, namespace), và gửi log đến một backend lưu trữ tập trung (như Elasticsearch, Loki, hoặc một dịch vụ cloud).
- Ưu điểm: Hiệu quả, tự động thu thập log từ tất cả các Pod trên Node mà không cần thay đổi ứng dụng.
2. Sidecar Logging Container: Kiến trúc này được sử dụng trong các trường hợp đặc biệt.
- Cách hoạt động: Một container "sidecar" được thêm vào mỗi Pod của ứng dụng.
- Ứng dụng chính có thể ghi log vào một file trong một
Volumedùng chung, hoặc sidecar có thể "đuôi" (tail)stdout/stderrcủa ứng dụng chính. - Container sidecar sau đó sẽ chịu trách nhiệm gửi log đến backend tập trung.
- Trường hợp sử dụng:
- Khi ứng dụng không thể dễ dàng sửa đổi để ghi ra
stdout/stderr(ví dụ: một ứng dụng cũ ghi vào file cố định). - Khi bạn cần xử lý log một cách chuyên biệt cho từng ứng dụng.
- Khi ứng dụng không thể dễ dàng sửa đổi để ghi ra
- Nhược điểm: Tốn nhiều tài nguyên hơn (mỗi Pod có thêm một container), phức tạp hơn để cấu hình.
10.1.3. Bộ công cụ EFK/Loki-Promtail
EFK Stack (Elasticsearch, Fluentd, Kibana):
- Fluentd: Agent (
DaemonSet) thu thập, xử lý và gửi log. - Elasticsearch: Một công cụ tìm kiếm và phân tích mạnh mẽ, dùng để lưu trữ và đánh chỉ mục (index) log.
- Kibana: Giao diện web để tìm kiếm, trực quan hóa và phân tích log trong Elasticsearch.
- Đây là một bộ công cụ rất mạnh mẽ nhưng cũng khá phức tạp và tốn tài nguyên (đặc biệt là Elasticsearch).
- Fluentd: Agent (
Loki, Promtail, và Grafana:
- Promtail: Một agent cực kỳ nhẹ (
DaemonSet) được thiết kế chuyên biệt để thu thập log và gửi cho Loki. - Loki: Backend lưu trữ log, được phát triển bởi Grafana Labs. Triết lý của Loki là "chỉ đánh chỉ mục metadata, không phải nội dung log". Nó chỉ index các
label(giống Prometheus) nhưpod,namespace,app. Điều này giúp Loki cực kỳ hiệu quả về chi phí lưu trữ và tài nguyên so với Elasticsearch. - Grafana: Giao diện để truy vấn (bằng ngôn ngữ LogQL) và hiển thị log từ Loki, cũng như metrics từ Prometheus, tạo ra một nền tảng quan sát hợp nhất.
- Bộ công cụ này đang ngày càng trở nên phổ biến vì sự đơn giản và hiệu quả của nó.
- Promtail: Một agent cực kỳ nhẹ (
10.2. Monitoring
Nếu logging cho chúng ta biết "điều gì đã xảy ra", thì monitoring cho chúng ta biết "hệ thống đang hoạt động như thế nào" ở một góc độ tổng hợp. Monitoring tập trung vào việc thu thập, xử lý và hiển thị các chỉ số (metrics) dạng số theo thời gian.
10.2.1. Các chỉ số quan trọng cần theo dõi
Có hai phương pháp luận phổ biến để xác định những gì cần theo dõi:
- The RED Method (Rate, Errors, Duration): Dành cho các hệ thống dựa trên request.
- Rate: Số lượng request mỗi giây.
- Errors: Số lượng request thất bại mỗi giây.
- Duration: Thời gian xử lý mỗi request (thường là phân vị 95, 99).
- The USE Method (Utilization, Saturation, Errors): Dành cho việc theo dõi tài nguyên.
- Utilization: Mức độ sử dụng tài nguyên (ví dụ: CPU đang sử dụng 80%).
- Saturation: Mức độ "bận rộn" của tài nguyên, thường biểu thị qua hàng đợi (ví dụ: CPU load average).
- Errors: Số lượng lỗi của tài nguyên (ví dụ: lỗi mạng, lỗi ổ đĩa).
10.2.2. Kiến trúc Metrics trong Kubernetes
cAdvisor: Một thành phần được tích hợp sẵn trongkubelet. Nó tự động thu thập các metrics cơ bản về hiệu suất của container và Node (sử dụng CPU, memory, network, file system).Metrics Server: Một thành phần cluster-level, thu thập dữ liệu từ tất cả cáccAdvisorvà tổng hợp chúng lại. Nó cung cấp một API tối giản (metrics.k8s.io) cho phép bạn xem mức sử dụng tài nguyên hiện tại. Đây là nguồn dữ liệu cho các lệnh nhưkubectl top podvàkubectl top node.Metrics Serverkhông lưu trữ dữ liệu lịch sử.- Hệ thống Monitoring đầy đủ (Prometheus): Để có thể giám sát một cách toàn diện, lưu trữ dữ liệu lịch sử và thiết lập cảnh báo, bạn cần một giải pháp như Prometheus.
10.2.3. Prometheus và Grafana: Tiêu chuẩn vàng của monitoring
Prometheus:
- Là một dự án tốt nghiệp của CNCF và là tiêu chuẩn de facto cho monitoring trong hệ sinh thái cloud-native.
- Mô hình Pull-based: Prometheus Server định kỳ "kéo" (scrape) metrics từ các endpoint HTTP (
/metrics) mà các ứng dụng hoặc các "exporter" phơi bày ra. - Service Discovery: Prometheus tích hợp hoàn hảo với Kubernetes. Nó có thể tự động phát hiện tất cả các Pod, Service, Node trong cluster và tìm ra các endpoint
/metricsđể scrape. - PromQL: Một ngôn ngữ truy vấn cực kỳ mạnh mẽ và linh hoạt để bạn có thể tổng hợp, tính toán và phân tích dữ liệu time-series.
- Alertmanager: Một thành phần đi kèm để xử lý việc gửi cảnh báo (alert) qua email, Slack, PagerDuty, v.v.
Grafana:
- Là công cụ trực quan hóa hàng đầu cho dữ liệu time-series.
- Nó có thể kết nối với Prometheus (và nhiều nguồn dữ liệu khác) để tạo ra các dashboard đẹp mắt, tương tác, giúp bạn dễ dàng theo dõi sức khỏe của hệ thống.
10.3. Debugging
Khi logging và monitoring cho thấy có vấn đề, bạn cần các công cụ để "lặn sâu" vào hệ thống và tìm ra gốc rễ của vấn đề.
10.3.1. Bộ tứ kubectl cho Debugging
kubectl logs: Luôn là điểm bắt đầu. Xem log của Pod để tìm các thông báo lỗi hoặc stack trace.kubectl logs <pod-name>kubectl logs -f <pod-name>(theo dõi log)kubectl logs --previous <pod-name>(xem log của container đã bị khởi động lại)
kubectl describe pod <pod-name>: Cung cấp một "bản tóm tắt" toàn diện về Pod. Hãy đặc biệt chú ý đến phần Events ở cuối cùng. Phần này ghi lại các sự kiện quan trọng trong vòng đời của Pod, ví dụ như "Failed to pull image", "Liveness probe failed", "Node is out of memory". Rất nhiều vấn đề có thể được chẩn đoán chỉ bằng cách đọc Events.kubectl get events --sort-by='.lastTimestamp': Xem danh sách tất cả các sự kiện gần đây trong namespace, giúp bạn có một cái nhìn tổng quan về những gì đang xảy ra.kubectl exec -it <pod-name> -- /bin/bash: "Nhảy" vào bên trong một container đang chạy. Đây là công cụ cực kỳ mạnh mẽ để:- Kiểm tra xem các file cấu hình đã được mount đúng chưa (
ls,cat). - Kiểm tra kết nối mạng từ bên trong Pod (
ping,curl,netstat). - Kiểm tra các biến môi trường (
env).
- Kiểm tra xem các file cấu hình đã được mount đúng chưa (
10.3.2. Debugging các lỗi Pod phổ biến
Pending: Pod bị kẹt ở trạng tháiPending. Dùngkubectl describeđể xem lý do.- Lý do phổ biến: Cluster không đủ tài nguyên (CPU/Memory) để đáp ứng
requestscủa Pod; Pod yêu cầu mộtVolumekhông tồn tại hoặc không có sẵn;taints/tolerationskhông khớp.
- Lý do phổ biến: Cluster không đủ tài nguyên (CPU/Memory) để đáp ứng
ImagePullBackOff/ErrImagePull:kubeletkhông thể kéo container image.- Lý do phổ biến: Sai tên image hoặc tag; image không tồn tại; cần thông tin xác thực để kéo image từ private registry nhưng
Secret(loạidockerconfigjson) chưa được cung cấp.
- Lý do phổ biến: Sai tên image hoặc tag; image không tồn tại; cần thông tin xác thực để kéo image từ private registry nhưng
CrashLoopBackOff: Container khởi động, bị crash, rồikubeletlại cố gắng khởi động lại nó, tạo thành một vòng lặp.- Đây là một triệu chứng, không phải nguyên nhân. Nguyên nhân thực sự là do ứng dụng của bạn bị crash ngay khi khởi động.
- Cách debug: Dùng
kubectl logs --previous <pod-name>để xem log của lần chạy trước khi nó bị crash. Rất có thể bạn sẽ thấy một lỗi nghiêm trọng (panic, unhandled exception) ở đó.
OOMKilled: Container đã cố gắng sử dụng nhiều Memory hơn mứclimitcủa nó và đã bịkubeletgiết.- Cách debug: Tăng
memory limithoặc tối ưu hóa việc sử dụng memory của ứng dụng.
- Cách debug: Tăng
10.3.3. Ephemeral Containers: Debugging live
Đôi khi, bạn cần debug một Pod đang chạy nhưng image của nó lại không chứa các công cụ cần thiết (như curl, net-tools). Việc exec vào và cài đặt chúng sẽ làm thay đổi container.
Ephemeral Containers (tính năng ổn định từ Kubernetes 1.25) cho phép bạn "gắn" một container gỡ lỗi tạm thời vào một Pod đang chạy mà không cần khởi động lại nó.
# Gắn một container tên 'debugger' dùng image 'busybox' vào pod 'my-pod'
kubectl debug -it my-pod --image=busybox --target=my-app-containerLệnh này sẽ tạo một container mới trong Pod, chia sẻ chung network và process namespace với container my-app-container, cho phép bạn sử dụng các công cụ từ busybox để kiểm tra môi trường của container chính.
10.3.4. kubectl port-forward: Truy cập ứng dụng trực tiếp
Khi bạn muốn truy cập trực tiếp vào một port của Pod từ máy local của mình để test hoặc debug (ví dụ: kết nối một debugger từ IDE, truy cập vào một web UI nội bộ), port-forward là công cụ dành cho bạn.
# Chuyển tiếp port 8080 trên máy local đến port 80 của pod 'my-web-pod'
kubectl port-forward my-web-pod 8080:80Bây giờ, bạn có thể mở trình duyệt và truy cập http://localhost:8080, traffic sẽ được chuyển tiếp an toàn đến Pod trong cluster.
Kết luận Chương 10: Logging, Monitoring, và Debugging là ba trụ cột của khả năng quan sát hệ thống. Bằng cách áp dụng triết lý ghi log ra stdout/stderr, triển khai các hệ thống giám sát mạnh mẽ như Prometheus, và thành thạo các công cụ gỡ lỗi của kubectl, bạn có thể tự tin vận hành và duy trì sự ổn định cho các ứng dụng phức tạp trên Kubernetes. Với những kỹ năng này, bạn không chỉ là một người xây dựng ứng dụng, mà còn là một người "bác sĩ" có khả-năng-chẩn-đoán và "chữa bệnh" cho hệ thống của mình.
Chương 11: Tối Ưu Hóa Quy Trình Phát Triển (Development Workflow)
- Chương 11.1. Vòng lặp phát triển: Code -> Build -> Deploy -> Test.
- Chương 11.2.
Skaffold: Tự động hóa vòng lặp phát triển trên Kubernetes. - Chương 11.3.
Telepresence: Phát triển và debug service cục bộ như thể nó đang chạy trong cluster. - Chương 11.4.
DevSpace: Một lựa chọn mạnh mẽ khác. - Chương 11.5. Xây dựng Docker image hiệu quả cho Kubernetes.
Phần IV: Helm - Trình Quản Lý Gói cho Kubernetes
Chương 12: Giới Thiệu về Helm
- 12.1. Helm là gì và tại sao nó cần thiết?
- 12.2. Các khái niệm cốt lõi: Chart, Release, Repository.
- 12.3. Kiến trúc Helm (Helm 3).
- 12.4. Cài đặt và cấu hình Helm.
Chương 13: Sử Dụng Helm Chart
- 13.1. Tìm kiếm Chart từ các repository (Artifact Hub).
- 13.2. Cài đặt một Chart (
helm install). - 13.3. Tùy chỉnh Chart với file
values.yaml. - 13.4. Quản lý các Release (
helm list,helm status,helm upgrade,helm rollback,helm uninstall).
Chương 14: Xây Dựng Helm Chart của Riêng Bạn
- 14.1. Cấu trúc của một Chart (
Chart.yaml,values.yaml,templates/,charts/). - 14.2. Go Templating Engine: Ngôn ngữ của Helm.
- 14.2.1. Biến, hàm, và pipelines.
- 14.2.2. Các đối tượng tích hợp sẵn (
.Values,.Release,.Chart). - 14.2.3. Luồng điều khiển (if/else, range).
- 14.2.4. Named Templates (
_helpers.tpl).
- 14.3. Quản lý các Chart phụ thuộc (Dependencies).
- 14.4.
helm lintvàhelm template: Debugging Chart của bạn. - 15.5. Đóng gói và chia sẻ Chart (
helm package, Chart Repository).
- 14.1. Cấu trúc của một Chart (
Phần V: Các Chủ Đề Nâng Cao và Mở Rộng
Chương 15: Bảo Mật trong Kubernetes cho Developer
- 15.1.
RBAC(Role-Based Access Control): Ai được làm gì?- 15.1.1.
Role,ClusterRole,RoleBinding,ClusterRoleBinding.
- 15.1.1.
- 15.2.
ServiceAccount: Định danh cho ứng dụng. - 15.3.
PodSecurityPolicy/Pod Security Admission. - 15.4.
NetworkPolicy: Tường lửa cho Pods. - 15.5. Quét lỗ hổng bảo mật trong container image.
- 15.1.
Chương 16: CI/CD với Kubernetes
- 16.1. Tổng quan về CI/CD trong thế giới Kubernetes.
- 16.2. Tích hợp Kubernetes với Jenkins.
- 16.3. Tích hợp Kubernetes với GitLab CI/CD.
- 16.4.
Argo CD: GitOps - "Infrastructure as Code" cho Kubernetes. - 16.5.
Flux CD: Một lựa chọn GitOps phổ biến khác.
Chương 17: Service Mesh - Quản Lý Giao Tiếp Giữa Các Service
- 17.1. Service Mesh là gì?
- 17.2.
Istio: Giới thiệu và kiến trúc. - 17.3.
Linkerd: Đơn giản và hiệu quả. - 17.4. Các tính năng chính: Traffic Management, Observability, Security.
Chương 18: Mở Rộng Kubernetes với Operators và CRDs
- 18.1.
Custom Resource Definitions(CRDs): Mở rộng Kubernetes API. - 18.2.
Operator Pattern: Tự động hóa quản lý ứng dụng phức tạp. - 18.3. Xây dựng một Operator đơn giản với
Operator SDKhoặcKubebuilder.
- 18.1.
Phụ Lục
- A: Bảng thuật ngữ Kubernetes.
- B: Tổng hợp các lệnh
kubectlhữu ích. - C: Các lỗi thường gặp và cách khắc phục.
- D: Tài liệu tham khảo và các khóa học đề xuất.
Phần III: Vận Hành và Tối Ưu Hóa cho Developer
Chương 9: Health Checks và Quản Lý Tài Nguyên
Việc triển khai được một ứng dụng chỉ là bước khởi đầu. Để vận hành một hệ thống đáng tin cậy, chúng ta cần trả lời hai câu hỏi quan trọng:
- Làm sao để biết ứng dụng của chúng ta vẫn đang hoạt động bình thường và sẵn sàng phục vụ người dùng?
- Làm sao để đảm bảo ứng dụng có đủ tài nguyên (CPU, Memory) để chạy, nhưng cũng không chiếm dụng quá mức gây ảnh hưởng đến các ứng dụng khác?
Chương này sẽ đi sâu vào hai cơ chế cốt lõi của Kubernetes giúp giải quyết những vấn đề trên: Health Checks (Probes) và Resource Management (Requests & Limits).
9.1. Liveness Probe: Pod của bạn có còn "sống"?
Vấn đề: Đôi khi, một ứng dụng vẫn đang chạy (tiến trình process vẫn tồn tại) nhưng lại rơi vào trạng thái không thể hoạt động được, ví dụ như bị deadlock, hết bộ nhớ, hoặc một vòng lặp vô hạn. Từ bên ngoài, tiến trình vẫn "sống", nhưng nó không còn khả năng xử lý yêu cầu hay làm bất cứ việc gì hữu ích.
Giải pháp: Liveness Probe (Thăm dò sự sống) là một cơ chế cho phép kubelet kiểm tra xem một container có còn hoạt động đúng cách hay không.
- Nếu Liveness Probe thành công:
kubeletkhông làm gì cả. - Nếu Liveness Probe thất bại:
kubeletsẽ giết (kill) container đó và khởi động lại nó theorestartPolicycủa Pod.
Hành động "giết và khởi động lại" này cực kỳ hiệu quả trong việc tự động phục hồi các ứng dụng bị treo.
Kubernetes cung cấp ba cách để thực hiện một probe:
- HTTP Probe (
httpGet):kubeletgửi một yêu cầu HTTP GET đến một endpoint cụ thể trong container của bạn. Nếu nhận được mã trả về trong khoảng 200-399, probe được coi là thành công. - TCP Probe (
tcpSocket):kubeletcố gắng mở một kết nối TCP đến một port cụ thể trong container. Nếu kết nối thành công, probe được coi là thành công. - Command Probe (
exec):kubeletthực thi một lệnh bên trong container. Nếu lệnh trả về exit code 0, probe được coi là thành công.
Ví dụ về Liveness Probe:
apiVersion: v1
kind: Pod
metadata:
name: liveness-pod
spec:
containers:
- name: my-app
image: my-app-image
livenessProbe:
httpGet:
path: /healthz # Endpoint kiểm tra sức khỏe
port: 8080
initialDelaySeconds: 15 # Chờ 15 giây sau khi container khởi động mới bắt đầu probe
periodSeconds: 20 # Thực hiện probe mỗi 20 giây
timeoutSeconds: 1 # Coi là thất bại nếu không nhận được phản hồi sau 1 giây
failureThreshold: 3 # Coi là thất bại thực sự sau 3 lần probe liên tiếp thất bại9.2. Readiness Probe: Pod đã sẵn sàng nhận request chưa?
Vấn đề: Một ứng dụng có thể đã khởi động (liveness probe thành công) nhưng chưa sẵn sàng để nhận traffic. Ví dụ:
- Một ứng dụng Java cần thời gian để khởi tạo Spring context, nạp dữ liệu vào cache.
- Một ứng dụng cần kết nối đến database và thực hiện các migration ban đầu.
Nếu Service gửi traffic đến Pod ngay khi nó vừa khởi động, người dùng có thể sẽ gặp lỗi.
Giải pháp: Readiness Probe (Thăm dò sự sẵn sàng) được dùng để cho Kubernetes biết khi nào một container đã sẵn sàng để bắt đầu nhận traffic.
- Nếu Readiness Probe thành công:
kubeletsẽ đánh dấu Pod làReady.Servicesẽ bắt đầu đưa Pod này vào danh sách các endpoint hợp lệ và gửi traffic đến nó. - Nếu Readiness Probe thất bại:
kubeletsẽ đánh dấu Pod làNotReady.Servicesẽ xóa Pod này khỏi danh sách endpoint. Traffic sẽ không được gửi đến nó nữa cho đến khi probe thành công trở lại.
Quan trọng là, nếu Readiness Probe thất bại, kubelet sẽ không khởi động lại container. Nó chỉ tạm thời "cách ly" Pod ra khỏi luồng traffic.
Tại sao Readiness Probe lại quan trọng cho Rolling Update? Khi bạn thực hiện một Deployment rolling update, Kubernetes sẽ chỉ coi một Pod mới là "sẵn sàng" khi Readiness Probe của nó thành công. Điều này đảm bảo rằng Pod mới chỉ nhận traffic khi nó đã thực sự sẵn sàng 100%, giúp quá trình cập nhật diễn ra mượt mà không gây lỗi cho người dùng (zero-downtime deployment).
Ví dụ về Readiness Probe: Cấu hình của Readiness Probe hoàn toàn tương tự Liveness Probe.
apiVersion: v1
kind: Pod
metadata:
name: readiness-pod
spec:
containers:
- name: my-app
image: my-app-image
readinessProbe:
httpGet:
path: /ready
port: 8080
initialDelaySeconds: 5
periodSeconds: 10Best Practice: Luôn luôn định nghĩa cả
LivenessvàReadinessprobe.Livenessđể khởi động lại ứng dụng bị treo,Readinessđể đảm bảo cập nhật an toàn và không gửi traffic đến ứng dụng chưa sẵn sàng. Endpoint củaReadinessprobe thường phức tạp hơn, có thể cần kiểm tra cả kết nối đến database, message queue, v.v.
9.3. Startup Probe: Dành cho các ứng dụng khởi động chậm
Vấn đề: Một số ứng dụng (đặc biệt là các ứng dụng Java cũ hoặc các ứng dụng cần thực hiện nhiều tác vụ nặng khi khởi động) có thể mất vài phút để bắt đầu. Nếu initialDelaySeconds của Liveness Probe quá ngắn, kubelet có thể giết chết container trước khi nó kịp khởi động xong, gây ra một vòng lặp khởi động lại không hồi kết (CrashLoopBackOff).
Giải pháp: Startup Probe (Thăm dò khởi động) được thiết kế đặc biệt cho trường hợp này.
- Khi
Startup Probeđược định nghĩa, tất cả các probe khác sẽ bị vô hiệu hóa cho đến khiStartup Probethành công. Startup Probecó một khoảng thời gian dài (failureThreshold*periodSeconds) để hoàn thành.- Nếu Startup Probe thành công:
kubeletsẽ bắt đầu thực hiệnLivenessvàReadinessprobe như bình thường. - Nếu Startup Probe thất bại (vượt quá thời gian cho phép):
kubeletsẽ giết và khởi động lại container.
Ví dụ về Startup Probe:
startupProbe:
httpGet:
path: /healthz
port: 8080
failureThreshold: 30 # Thử lại 30 lần
periodSeconds: 10 # Mỗi lần cách nhau 10 giây
# => Container có tổng cộng 30 * 10 = 300 giây (5 phút) để khởi động.9.4. Requests và Limits: Quản lý CPU và Memory
Trong một cluster chia sẻ, việc quản lý tài nguyên là tối quan trọng. Kubernetes cho phép bạn chỉ định lượng CPU và Memory mà mỗi container cần và được phép sử dụng thông qua hai tham số: requests và limits.
requests (Yêu cầu):
- Ý nghĩa: Lượng tài nguyên được đảm bảo (guaranteed) cho container.
- Cách hoạt động:
- Memory Request: Kubernetes đảm bảo container sẽ luôn có ít nhất lượng memory này.
- CPU Request: Kubernetes đảm bảo container sẽ nhận được phần CPU tương ứng. CPU là tài nguyên có thể "nén" được (compressible), nên nếu có CPU nhàn rỗi, container có thể dùng nhiều hơn mức request.
- Vai trò với Scheduler:
kube-schedulersử dụngrequestsđể quyết định đặt Pod ở đâu. Nó sẽ chỉ đặt Pod lên một Node nếu Node đó có đủ tài nguyên chưa được cấp phát để đáp ứngrequestscủa Pod.
limits (Giới hạn):
- Ý nghĩa: Lượng tài nguyên tối đa mà container được phép sử dụng.
- Cách hoạt động:
- Memory Limit: Nếu container cố gắng sử dụng nhiều memory hơn
limit, nó sẽ bị giết với lỗi OOMKilled (Out of Memory). - CPU Limit: Nếu container cố gắng sử dụng nhiều CPU hơn
limit, nó sẽ bị điều tiết (throttled), tức là hiệu năng sẽ bị giảm xuống để không vượt quá giới hạn. Container sẽ không bị giết.
- Memory Limit: Nếu container cố gắng sử dụng nhiều memory hơn
Đơn vị đo lường:
- Memory:
Ki(Kibibyte),Mi(Mebibyte),Gi(Gibibyte),Ti(Tebibyte). - CPU:
m(millicpu hoặc millicore).1000mtương đương với 1 vCPU/core.500mlà nửa core.
Ví dụ:
resources:
requests:
memory: "64Mi"
cpu: "250m" # 0.25 core
limits:
memory: "128Mi"
cpu: "500m" # 0.5 coreBest Practice: Luôn luôn đặt
requestsvàlimitscho mọi container trong môi trường production. Điều này giúp Scheduler đưa ra quyết định tốt hơn, tránh tình trạng "hàng xóm ồn ào" (một Pod dùng quá nhiều tài nguyên ảnh hưởng đến các Pod khác), và làm cho cluster hoạt động ổn định hơn.
9.5. Quality of Service (QoS) Classes
Dựa trên cách bạn đặt requests và limits, Kubernetes sẽ tự động gán cho Pod của bạn một trong ba lớp Chất lượng Dịch vụ (QoS). Lớp QoS này quyết định Pod nào sẽ bị giết trước tiên khi Node cạn kiệt tài nguyên (đặc biệt là Memory).
Guaranteed(Đảm bảo):- Điều kiện: Mọi container trong Pod phải có cả
memory requestvàmemory limit, và chúng phải bằng nhau. Tương tự cho CPU. - Đặc điểm: Đây là các Pod có độ ưu tiên cao nhất. Chúng sẽ là những Pod cuối cùng bị giết nếu Node hết tài nguyên.
- Ví dụ:yaml
resources: requests: memory: "128Mi" cpu: "500m" limits: memory: "128Mi" cpu: "500m"
- Điều kiện: Mọi container trong Pod phải có cả
Burstable(Có thể bùng nổ):- Điều kiện: Ít nhất một container trong Pod có
requestnhưnglimitlớn hơnrequest, hoặc chỉ córequestmà không cólimit. - Đặc điểm: Các Pod này được phép "bùng nổ" sử dụng nhiều tài nguyên hơn mức request nếu có tài nguyên nhàn rỗi trên Node. Chúng có độ ưu tiên trung bình và sẽ bị giết sau các Pod
BestEffort. - Ví dụ:yaml
resources: requests: memory: "64Mi" cpu: "250m" limits: memory: "128Mi" cpu: "500m"
- Điều kiện: Ít nhất một container trong Pod có
BestEffort(Nỗ lực tốt nhất):- Điều kiện: Không có bất kỳ container nào trong Pod có
requestshoặclimits. - Đặc điểm: Đây là các Pod có độ ưu tiên thấp nhất. Chúng sẽ là những Pod đầu tiên bị giết khi Node hết tài nguyên. Chỉ nên dùng cho các tác vụ có độ ưu tiên thấp, không quan trọng.
- Điều kiện: Không có bất kỳ container nào trong Pod có
9.6. ResourceQuota và LimitRange: Giới hạn tài nguyên ở mức Namespace
Requests và limits được đặt ở cấp độ container. Nhưng làm thế nào để một Admin có thể kiểm soát tổng lượng tài nguyên mà một team hoặc một dự án được phép sử dụng?
ResourceQuota:- Cho phép Admin đặt ra giới hạn tổng tài nguyên cho một
namespace. - Ví dụ: Namespace
team-achỉ được phép yêu cầu tổng cộng 20 core CPU và 64GiB Memory, và chỉ được tạo tối đa 10Service. - Nếu việc tạo một tài nguyên mới (Pod, Service) làm vượt quá quota, yêu cầu sẽ bị từ chối.
- Cho phép Admin đặt ra giới hạn tổng tài nguyên cho một
LimitRange:- Cho phép Admin đặt ra các giới hạn mặc định, giới hạn tối thiểu/tối đa cho các tài nguyên trong một
namespace. - Ví dụ:
- Nếu một Pod được tạo mà không có
requests/limits, nó sẽ tự động được gán giá trị mặc định. - Đảm bảo không ai có thể tạo một Pod yêu cầu quá nhiều tài nguyên (ví dụ: 100GiB Memory).
- Đảm bảo mọi Pod đều có
requesttối thiểu.
- Nếu một Pod được tạo mà không có
- Cho phép Admin đặt ra các giới hạn mặc định, giới hạn tối thiểu/tối đa cho các tài nguyên trong một
Hai công cụ này rất quan trọng cho các môi trường đa người dùng (multi-tenant), giúp đảm bảo sự công bằng và ổn định cho toàn bộ cluster.
Kết luận Chương 9: Việc cấu hình Health Checks và Resource Management là một bước chuyển từ "chạy được" sang "chạy tốt và đáng tin cậy". Liveness, Readiness, và Startup probes là những người bảo vệ thầm lặng, đảm bảo ứng dụng của bạn luôn khỏe mạnh và các bản cập nhật diễn ra an toàn. Requests và Limits là nền tảng của sự ổn định và khả năng dự đoán trong một môi trường chia sẻ tài nguyên. Nắm vững các khái niệm này, bạn đã tiến một bước dài trên con đường trở thành một kỹ sư vận hành ứng dụng chuyên nghiệp trên Kubernetes. Tiếp theo, chúng ta sẽ khám phá bộ công cụ cần thiết để "nhìn" vào bên trong hệ thống: Logging, Monitoring và Debugging.
Chương 10: Logging, Monitoring và Debugging
Chúng ta đã học cách triển khai, kết nối, cấu hình và quản lý tài nguyên cho ứng dụng. Nhưng khi hệ thống đã chạy, làm thế nào chúng ta biết được điều gì đang thực sự xảy ra bên trong? Khi có lỗi, làm thế nào để tìm ra nguyên nhân? Đây là lúc bộ ba "thần thánh" của vận hành hệ thống vào cuộc: Logging (Ghi log), Monitoring (Giám sát), và Debugging (Gỡ lỗi).
Trong một hệ thống phân tán và năng động như Kubernetes, việc "quan sát" (Observability) không còn là một tùy chọn, mà là một yêu cầu bắt buộc.
10.1. Logging
Logging là việc ghi lại các sự kiện rời rạc, theo thời gian đã xảy ra trong ứng dụng. Mỗi dòng log là một "dấu vết" về một hành động hoặc một sự kiện cụ thể.
10.1.1. Triết lý Logging trong Kubernetes: Ghi log ra stdout và stderr
Trong môi trường container, cách tiếp cận tốt nhất và đơn giản nhất là để ứng dụng của bạn ghi log trực tiếp ra hai luồng (stream) tiêu chuẩn: standard output (stdout) cho các log thông thường và standard error (stderr) cho các log lỗi.
Tại sao lại như vậy?
- Tách biệt mối quan tâm: Ứng dụng của bạn chỉ cần tập trung vào việc tạo ra log. Nó không cần quan tâm đến việc log sẽ được lưu trữ ở đâu, xoay vòng (rotate) như thế nào, hay gửi đi đâu. Việc định tuyến và xử lý log là nhiệm vụ của hạ tầng.
- Tính di động: Ứng dụng của bạn không bị phụ thuộc vào một hệ thống file cụ thể. Nó có thể chạy ở bất cứ đâu.
- Tích hợp tự nhiên: Container runtime (như
containerd) vàkubeletđược thiết kế để tự động thu thập các luồngstdoutvàstderrnày.
Khi bạn chạy lệnh kubectl logs <tên-pod>, bạn đang thực chất đọc lại các bản ghi mà kubelet đã thu thập từ stdout và stderr của container.
10.1.2. Kiến trúc logging trong Kubernetes
Việc dùng kubectl logs chỉ phù hợp để xem log nhanh của một Pod. Khi Pod bị xóa, log của nó cũng biến mất. Để có một hệ thống logging bền bỉ và tập trung, chúng ta cần một giải pháp ở cấp độ cluster. Có hai kiến trúc chính:
1. Node-level Logging Agent (Agent ghi log ở cấp độ Node): Đây là kiến trúc phổ biến và được khuyến khích nhất.
- Cách hoạt động: Một agent chuyên dụng (như
Fluentd,Promtail,Vector) được triển khai trên mỗi Worker Node dưới dạng mộtDaemonSet. - Agent này sẽ tự động truy cập vào các file log mà
kubelettạo ra trên Node (thường ở/var/log/pods/...). - Nó sẽ đọc, xử lý (ví dụ: thêm metadata như tên Pod, namespace), và gửi log đến một backend lưu trữ tập trung (như Elasticsearch, Loki, hoặc một dịch vụ cloud).
- Ưu điểm: Hiệu quả, tự động thu thập log từ tất cả các Pod trên Node mà không cần thay đổi ứng dụng.
2. Sidecar Logging Container: Kiến trúc này được sử dụng trong các trường hợp đặc biệt.
- Cách hoạt động: Một container "sidecar" được thêm vào mỗi Pod của ứng dụng.
- Ứng dụng chính có thể ghi log vào một file trong một
Volumedùng chung, hoặc sidecar có thể "đuôi" (tail)stdout/stderrcủa ứng dụng chính. - Container sidecar sau đó sẽ chịu trách nhiệm gửi log đến backend tập trung.
- Trường hợp sử dụng:
- Khi ứng dụng không thể dễ dàng sửa đổi để ghi ra
stdout/stderr(ví dụ: một ứng dụng cũ ghi vào file cố định). - Khi bạn cần xử lý log một cách chuyên biệt cho từng ứng dụng.
- Khi ứng dụng không thể dễ dàng sửa đổi để ghi ra
- Nhược điểm: Tốn nhiều tài nguyên hơn (mỗi Pod có thêm một container), phức tạp hơn để cấu hình.
10.1.3. Bộ công cụ EFK/Loki-Promtail
- **EFK Stack (Elasticsearch, Fluentd
10.3. Debugging: Khi Mọi Thứ Không Như Ý
Debugging ứng dụng trong Kubernetes có thể là một thách thức, vì bạn không thể "ssh" vào một container một cách dễ dàng như với máy ảo. Tuy nhiên, Kubernetes cung cấp một bộ công cụ mạnh mẽ để bạn "nhìn" vào bên trong và tìm ra lỗi.
10.3.1. Các Lệnh Vàng: , ,
Đây là ba lệnh bạn sẽ sử dụng hàng ngày:
****: Lệnh cơ bản nhất, dùng để xem log (stdout/stderr) của một container trong Pod.
- : Stream log trực tiếp.
- : Xem log của container đã bị restart.
- : Xem log của một container cụ thể trong Pod đa container.
****: Cung cấp một cái nhìn tổng quan chi tiết về trạng thái của Pod. Đây là nơi đầu tiên cần tìm đến khi Pod không chạy được. Bạn sẽ thấy:
- Trạng thái (Status): , , , , .
- Events: Một lịch sử các sự kiện liên quan đến Pod. Đây là phần quan trọng nhất để chẩn đoán lỗi. Các lỗi như , , đều được hiển thị rõ ở đây cùng với lý do chi tiết.
- Thông tin về IP, Node, tài nguyên, volumes, ...
****: Mở một shell tương tác vào bên trong một container đang chạy. Điều này cực kỳ hữu ích để:
- Kiểm tra xem file cấu hình đã được mount đúng chưa.
- Kiểm tra kết nối mạng từ bên trong Pod ( Usage: ping [-t] [-a] [-n count] [-l size] [-f] [-i TTL] [-v TOS] [-r count] [-s count] [[-j host-list] | [-k host-list]] [-w timeout] [-R] [-S srcaddr] [-c compartment] [-p] [-4] [-6] target_name
Options: -t Ping the specified host until stopped. To see statistics and continue - type Control-Break; To stop - type Control-C. -a Resolve addresses to hostnames. -n count Number of echo requests to send. -l size Send buffer size. -f Set Don't Fragment flag in packet (IPv4-only). -i TTL Time To Live. -v TOS Type Of Service (IPv4-only. This setting has been deprecated and has no effect on the type of service field in the IP Header). -r count Record route for count hops (IPv4-only). -s count Timestamp for count hops (IPv4-only). -j host-list Loose source route along host-list (IPv4-only). -k host-list Strict source route along host-list (IPv4-only). -w timeout Timeout in milliseconds to wait for each reply. -R Use routing header to test reverse route also (IPv6-only). Per RFC 5095 the use of this routing header has been deprecated. Some systems may drop echo requests if this header is used. -S srcaddr Source address to use. -c compartment Routing compartment identifier. -p Ping a Hyper-V Network Virtualization provider address. -4 Force using IPv4. -6 Force using IPv6., ). * Chạy các lệnh gỡ lỗi đặc thù của ứng dụng.
10.3.2. Chẩn Đoán Các Lỗi Pod Phổ Biến
- ****: Pod đang bị kẹt ở trạng thái chờ. Dùng để xem lý do.
- ****: Scheduler không tìm thấy Node nào phù hợp. Lý do có thể là: không đủ tài nguyên (CPU/Memory), Node không khớp với hoặc , hoặc Node bị .
- ** / **: Kubelet không thể kéo image về. Lý do:
- Sai tên image hoặc tag.
- Không có quyền truy cập vào private registry (cần cấu hình ).
- Lỗi mạng.
- ****: Container đã khởi động nhưng bị crash ngay lập tức, và Kubelet đang cố gắng khởi động lại nó một cách vô vọng.
- Dùng để xem log của lần chạy bị crash trước đó. Lỗi thường nằm trong ứng dụng của bạn (ví dụ: không kết nối được database, lỗi cấu hình, bug trong code).
- Kiểm tra lại . Có thể probe của bạn quá khắt khe hoặc cấu hình sai, khiến Kubelet giết container một cách oan uổng.
10.3.3. : Công Cụ Debugging Hiện Đại
Vấn đề: Docker image của bạn được tối ưu cho production, không chứa các công cụ gỡ lỗi như , Usage: ping [-t] [-a] [-n count] [-l size] [-f] [-i TTL] [-v TOS] [-r count] [-s count] [[-j host-list] | [-k host-list]] [-w timeout] [-R] [-S srcaddr] [-c compartment] [-p] [-4] [-6] target_name
Options: -t Ping the specified host until stopped. To see statistics and continue - type Control-Break; To stop - type Control-C. -a Resolve addresses to hostnames. -n count Number of echo requests to send. -l size Send buffer size. -f Set Don't Fragment flag in packet (IPv4-only). -i TTL Time To Live. -v TOS Type Of Service (IPv4-only. This setting has been deprecated and has no effect on the type of service field in the IP Header). -r count Record route for count hops (IPv4-only). -s count Timestamp for count hops (IPv4-only). -j host-list Loose source route along host-list (IPv4-only). -k host-list Strict source route along host-list (IPv4-only). -w timeout Timeout in milliseconds to wait for each reply. -R Use routing header to test reverse route also (IPv6-only). Per RFC 5095 the use of this routing header has been deprecated. Some systems may drop echo requests if this header is used. -S srcaddr Source address to use. -c compartment Routing compartment identifier. -p Ping a Hyper-V Network Virtualization provider address. -4 Force using IPv4. -6 Force using IPv6., . Bạn không thể vào và làm gì nhiều.
Giải pháp: (từ Kubernetes 1.23+). Đây là một container đặc biệt bạn có thể "đính kèm" vào một Pod đang chạy để gỡ lỗi. Container này có thể chứa đầy đủ các công cụ bạn cần.
# Đính kèm một container tên 'debugger' dùng image 'busybox' vào pod 'my-app'
kubectl debug -it my-app --image=busybox --target=my-app-container -- /bin/shLệnh này sẽ tạo một ephemeral container và cho bạn một shell vào thẳng container đó, chia sẻ chung process namespace với container ứng dụng của bạn.
10.3.4. : Truy Cập Ứng Dụng Trực Tiếp
Đôi khi bạn muốn kết nối trực tiếp đến một port của Pod từ máy local của mình để gửi request gỡ lỗi mà không cần thông qua Service hay Ingress.
# Forward port 8080 trên máy local tới port 80 của pod 'my-pod'
kubectl port-forward my-pod 8080:80Bây giờ, bạn có thể mở trình duyệt và truy cập , request sẽ được chuyển thẳng đến Pod.
Chương 11: Tối Ưu Hóa Quy Trình Phát Triển (Development Workflow)
Mục tiêu của mọi developer là rút ngắn vòng lặp "viết code - thấy kết quả". Làm việc với Kubernetes có thể kéo dài vòng lặp này ra một cách đáng kể: sửa code, build lại Docker image, push image lên registry, cập nhật lại Deployment, chờ Pod mới khởi động... Quá trình này chậm chạp và tẻ nhạt. Chương này giới thiệu các công cụ và kỹ thuật để lấy lại tốc độ phát triển vốn có.
11.1. Vòng Lặp Phát Triển Điển Hình (và Chậm Chạp)
- Code: Lập trình viên sửa code trên máy local.
- Build: Chạy để tạo image mới.
- Push: Chạy để đẩy image lên một registry (Docker Hub, GCR, ECR...).
- Deploy: Chạy hoặc để cập nhật ứng dụng.
- Test: Chờ Pod mới sẵn sàng và kiểm tra kết quả.
Nếu có lỗi, quay lại bước 1. Mỗi vòng lặp có thể mất từ vài phút đến cả chục phút.
11.2. : Tự Động Hóa Toàn Bộ Vòng Lặp
Skaffold là một công cụ từ Google giúp tự động hóa hoàn toàn vòng lặp phát triển trên Kubernetes. Bạn chỉ cần chạy một lệnh duy nhất: .
Cách hoạt động: Skaffold theo dõi file code của bạn. Mỗi khi bạn lưu file, nó sẽ tự động:
- Build: Build lại Docker image (có thể build trên local Docker, hoặc trong chính cluster với Kaniko).
- Push: Push image lên registry (có thể bỏ qua nếu build trên local cluster như Minikube).
- Deploy: Deploy lại ứng dụng lên cluster (hỗ trợ kubectl controls the Kubernetes cluster manager.
Find more information at: https://kubernetes.io/docs/reference/kubectl/
Basic Commands (Beginner): create Create a resource from a file or from stdin expose Take a replication controller, service, deployment or pod and expose it as a new Kubernetes service run Run a particular image on the cluster set Set specific features on objects
Basic Commands (Intermediate): explain Get documentation for a resource get Display one or many resources edit Edit a resource on the server delete Delete resources by file names, stdin, resources and names, or by resources and label selector
Deploy Commands: rollout Manage the rollout of a resource scale Set a new size for a deployment, replica set, or replication controller autoscale Auto-scale a deployment, replica set, stateful set, or replication controller
Cluster Management Commands: certificate Modify certificate resources cluster-info Display cluster information top Display resource (CPU/memory) usage cordon Mark node as unschedulable uncordon Mark node as schedulable drain Drain node in preparation for maintenance taint Update the taints on one or more nodes
Troubleshooting and Debugging Commands: describe Show details of a specific resource or group of resources logs Print the logs for a container in a pod attach Attach to a running container exec Execute a command in a container port-forward Forward one or more local ports to a pod proxy Run a proxy to the Kubernetes API server cp Copy files and directories to and from containers auth Inspect authorization debug Create debugging sessions for troubleshooting workloads and nodes events List events
Advanced Commands: diff Diff the live version against a would-be applied version apply Apply a configuration to a resource by file name or stdin patch Update fields of a resource replace Replace a resource by file name or stdin wait Experimental: Wait for a specific condition on one or many resources kustomize Build a kustomization target from a directory or URL
Settings Commands: label Update the labels on a resource annotate Update the annotations on a resource completion Output shell completion code for the specified shell (bash, zsh, fish, or powershell)
Subcommands provided by plugins:
Other Commands: api-resources Print the supported API resources on the server api-versions Print the supported API versions on the server, in the form of "group/version" config Modify kubeconfig files plugin Provides utilities for interacting with plugins version Print the client and server version information
Usage: kubectl [flags] [options]
Use "kubectl command --help" for more information about a given command. Use "kubectl options" for a list of global command-line options (applies to all commands)., Helm, Kustomize). 4. Stream logs: Tự động hiển thị log từ các Pod mới về terminal của bạn. 5. Port-forward: Tự động thiết lập port-forwarding để bạn truy cập ứng dụng.
Cấu hình Skaffold: Bạn định nghĩa quy trình trong một file .
apiVersion: skaffold/v2beta29
kind: Config
metadata:
name: my-app
build:
artifacts:
- image: my-app-image
context: . # Thư mục chứa Dockerfile
deploy:
kubectl:
manifests:
- k8s/deployment.yaml
portForward:
- resourceType: deployment
resourceName: my-app-deployment
port: 8080
localPort: 9000Chạy và bắt đầu code. Mọi thay đổi sẽ được tự động đồng bộ lên cluster trong vài giây.
11.3. : Ma Thuật Cho Microservices
Vấn đề: Hệ thống của bạn có hàng chục microservices. Để phát triển một service, bạn cần chạy cả chục service khác trên máy local, rất tốn tài nguyên và phức tạp.
Giải pháp: Telepresence. Nó cho phép bạn chạy một service duy nhất trên máy local, và service này hoạt động như thể nó đang nằm bên trong Kubernetes cluster. Nó có thể kết nối đến các service khác trong cluster qua tên DNS thông thường, và các service khác trong cluster cũng có thể gọi đến service trên máy local của bạn.
Cách hoạt động:
- Telepresence thay thế Pod của service bạn muốn debug bằng một proxy.
- Proxy này "intercept" (chặn) các request đến service đó và chuyển hướng chúng về máy local của bạn.
- Nó cũng tạo một kết nối mạng từ máy local của bạn vào cluster, cho phép code của bạn truy cập các service khác (ví dụ ).
Workflow:
- : Kết nối máy local vào mạng của cluster.
- : Bắt đầu chặn request.
- Chạy service của bạn trên máy local (ví dụ , ).
- Đặt breakpoint, debug, sửa code như bình thường. Mọi thay đổi có hiệu lực ngay lập tức mà không cần build lại image.
Telepresence là một công cụ thay đổi cuộc chơi khi làm việc với kiến trúc microservices phức tạp.
11.4. : Một Lựa Chọn Mạnh Mẽ Khác
DevSpace cũng là một công cụ mạnh mẽ tương tự Skaffold nhưng có thêm một số tính năng thú vị:
- Hot Reloading: Thay vì build lại toàn bộ image, DevSpace có thể đồng bộ file đã thay đổi trực tiếp vào container đang chạy, giúp tăng tốc độ hơn nữa.
- Tạo môi trường phát triển cô lập: Dễ dàng tạo các namespace riêng cho từng developer.
- Giao diện UI: Cung cấp một giao diện web để quản lý môi trường phát triển.
Lựa chọn giữa Skaffold, Telepresence, và DevSpace phụ thuộc vào nhu cầu cụ thể của bạn, nhưng cả ba đều giải quyết xuất sắc bài toán rút ngắn vòng lặp phát triển trên Kubernetes.
11.5. Xây Dựng Docker Image Hiệu Quả cho Kubernetes
Tốc độ build image ảnh hưởng trực tiếp đến tốc độ phát triển.
- Sử dụng Multi-stage builds: Tách biệt môi trường build và môi trường runtime. Image cuối cùng chỉ chứa những gì cần thiết để chạy ứng dụng, giúp giảm kích thước đáng kể.
- Tận dụng caching: Sắp xếp các layer trong Dockerfile một cách hợp lý. Những layer ít thay đổi (như cài đặt dependencies) nên được đặt lên trên, những layer thay đổi thường xuyên (như copy source code) nên đặt ở dưới.
- **Sử dụng **: Loại bỏ các file không cần thiết (như , logs, file tạm) khỏi context build để giảm thời gian build và kích thước image.
- Chọn base image nhỏ gọn: Bắt đầu với các image như , , hoặc thay vì đầy đủ.
Một image nhỏ gọn không chỉ build nhanh hơn mà còn push/pull nhanh hơn, giảm thời gian khởi động Pod và tăng cường bảo mật.
Phần IV: Helm - Trình Quản Lý Gói cho Kubernetes
Khi bạn bắt đầu làm việc với Kubernetes, bạn sẽ nhanh chóng nhận ra mình đang phải quản lý một số lượng lớn các file YAML: , , , ,... cho mỗi ứng dụng. Khi cần triển khai ứng dụng lên nhiều môi trường (dev, staging, production) với các cấu hình khác nhau, việc sao chép, sửa đổi và duy trì các file này trở thành một cơn ác mộng. Helm ra đời để giải quyết chính xác vấn đề này.
Chương 12: Giới Thiệu về Helm
Helm được ví như , , hoặc của Kubernetes. Nó là một trình quản lý gói giúp bạn dễ dàng tìm kiếm, chia sẻ, cài đặt và quản lý các ứng dụng Kubernetes.
12.1. Helm là gì và tại sao nó cần thiết?
Hãy tưởng tượng bạn muốn cài đặt WordPress lên cluster của mình. Bạn sẽ cần:
- Một cho WordPress.
- Một để expose WordPress.
- Một cho database (ví dụ: MariaDB).
- Một cho database.
- Một cho WordPress.
- Một cho database.
- Một để lưu mật khẩu.
Bạn phải tự viết và quản lý tất cả các file YAML này. Nếu có phiên bản mới, bạn phải tự tìm hiểu xem cần thay đổi những gì.
Với Helm, bạn chỉ cần một lệnh: . Helm sẽ tự động tạo ra tất cả các tài nguyên cần thiết với cấu hình chuẩn. Khi muốn nâng cấp, bạn chỉ cần chạy .
Lợi ích chính của Helm:
- Quản lý sự phức tạp: Đóng gói tất cả tài nguyên của một ứng dụng vào một đơn vị duy nhất (Chart).
- Tái sử dụng: Dễ dàng chia sẻ và tái sử dụng các ứng dụng phức tạp.
- Quản lý phiên bản: Dễ dàng cài đặt, nâng cấp, rollback các phiên bản của ứng dụng.
- Tùy biến: Dễ dàng tùy chỉnh cấu hình cho các môi trường khác nhau.
12.2. Các khái niệm cốt lõi
- Chart: Là một gói Helm. Nó là một tập hợp các file mô tả một bộ tài nguyên Kubernetes liên quan. Đây là đơn vị cơ bản để đóng gói và chia sẻ ứng dụng.
- Repository: Là nơi lưu trữ và chia sẻ các Chart. Giống như Docker Hub cho Docker image. là một trung tâm tìm kiếm các repository công khai lớn nhất.
- Release: Là một thực thể (instance) của một Chart đang chạy trong Kubernetes cluster. Khi bạn một Chart, một Release mới sẽ được tạo ra. Bạn có thể cài đặt cùng một Chart nhiều lần vào cùng một cluster, mỗi lần sẽ tạo ra một Release riêng biệt với tên khác nhau.
12.3. Kiến trúc Helm (Helm 3)
Phiên bản Helm 3 (ra mắt cuối 2019) đã có một sự thay đổi lớn về kiến trúc so với Helm 2.
- Loại bỏ Tiller: Helm 2 có một thành phần chạy trên server gọi là . Tiller có quyền hạn rất lớn trong cluster và là một rủi ro bảo mật. Helm 3 đã loại bỏ hoàn toàn Tiller.
- Client-only: Helm 3 là một công cụ chỉ chạy ở phía client. Nó sử dụng file của bạn (giống như kubectl controls the Kubernetes cluster manager.
Find more information at: https://kubernetes.io/docs/reference/kubectl/
Basic Commands (Beginner): create Create a resource from a file or from stdin expose Take a replication controller, service, deployment or pod and expose it as a new Kubernetes service run Run a particular image on the cluster set Set specific features on objects
Basic Commands (Intermediate): explain Get documentation for a resource get Display one or many resources edit Edit a resource on the server delete Delete resources by file names, stdin, resources and names, or by resources and label selector
Deploy Commands: rollout Manage the rollout of a resource scale Set a new size for a deployment, replica set, or replication controller autoscale Auto-scale a deployment, replica set, stateful set, or replication controller
Cluster Management Commands: certificate Modify certificate resources cluster-info Display cluster information top Display resource (CPU/memory) usage cordon Mark node as unschedulable uncordon Mark node as schedulable drain Drain node in preparation for maintenance taint Update the taints on one or more nodes
Troubleshooting and Debugging Commands: describe Show details of a specific resource or group of resources logs Print the logs for a container in a pod attach Attach to a running container exec Execute a command in a container port-forward Forward one or more local ports to a pod proxy Run a proxy to the Kubernetes API server cp Copy files and directories to and from containers auth Inspect authorization debug Create debugging sessions for troubleshooting workloads and nodes events List events
Advanced Commands: diff Diff the live version against a would-be applied version apply Apply a configuration to a resource by file name or stdin patch Update fields of a resource replace Replace a resource by file name or stdin wait Experimental: Wait for a specific condition on one or many resources kustomize Build a kustomization target from a directory or URL
Settings Commands: label Update the labels on a resource annotate Update the annotations on a resource completion Output shell completion code for the specified shell (bash, zsh, fish, or powershell)
Subcommands provided by plugins:
Other Commands: api-resources Print the supported API resources on the server api-versions Print the supported API versions on the server, in the form of "group/version" config Modify kubeconfig files plugin Provides utilities for interacting with plugins version Print the client and server version information
Usage: kubectl [flags] [options]
Use "kubectl [command] --help" for more information about a given command. Use "kubectl options" for a list of global command-line options (applies to all commands).) để tương tác trực tiếp với Kubernetes API Server. Điều này giúp Helm 3 an toàn hơn và tuân thủ theo cơ chế RBAC đã được cấu hình trong cluster của bạn.
12.4. Cài Đặt và Cấu Hình Helm
Cài đặt Helm rất đơn giản. Bạn có thể tải binary từ trang chủ của Helm hoặc cài đặt qua các trình quản lý gói.
# Trên macOS (sử dụng Homebrew)
brew install helm
# Trên Windows (sử dụng Chocolatey)
choco install kubernetes-helmSau khi cài đặt, kiểm tra phiên bản:
helm version
# version.BuildInfo{Version:"v3.8.1", GitCommit:"5cb9af4b1b271d118bF56b72b28237885e54a2a4", GitTreeState:"clean", GoVersion:"go1.17.5"}Thêm một repository phổ biến:
helm repo add bitnami https://charts.bitnami.com/bitnami
helm repo update # Cập nhật danh sách chart từ các repo đã thêmBây giờ bạn đã sẵn sàng để khám phá thế giới của Helm.
Chương 13: Sử Dụng Helm Chart
Chương này tập trung vào việc sử dụng các Chart đã có sẵn để triển khai ứng dụng.
13.1. Tìm kiếm Chart từ các repository
Cách tốt nhất để tìm Chart là sử dụng (artifacthub.io). Tuy nhiên, bạn cũng có thể tìm từ command line.
helm search repo wordpress
# NAME CHART VERSION APP VERSION DESCRIPTION
# bitnami/wordpress 13.0.6 5.9.1 Web publishing platform for building blogs and ...13.2. Cài đặt một Chart ()
Cú pháp:
# Cài đặt WordPress, tạo một release tên là 'my-blog'
helm install my-blog bitnami/wordpressSau khi chạy, Helm sẽ in ra một loạt thông tin hữu ích (phần ), bao gồm cách truy cập ứng dụng, lấy mật khẩu mặc định, v.v.
13.3. Tùy chỉnh Chart với file
Hầu hết các Chart đều cho phép bạn tùy chỉnh rất nhiều thứ. Các tùy chọn này được định nghĩa trong file của Chart.
Để xem tất cả các tùy chọn có thể tùy chỉnh của một Chart:
helm show values bitnami/wordpress > my-values.yamlLệnh này sẽ tải file mặc định của Chart về máy bạn. Bây giờ bạn có thể mở file , chỉnh sửa các giá trị theo ý muốn (ví dụ: đổi username, password, kích thước ổ đĩa,...).
Sau đó, cài đặt Chart với file values đã tùy chỉnh:
helm install my-custom-blog bitnami/wordpress -f my-values.yamlBạn cũng có thể ghi đè một giá trị cụ thể trực tiếp từ command line với cờ :
helm install my-fast-blog bitnami/wordpress --set mariadb.primary.persistence.size=2Gi13.4. Quản lý các Release
- ** / **: Liệt kê tất cả các release đang chạy.
- ****: Xem trạng thái chi tiết của một release, bao gồm các tài nguyên Kubernetes đã được tạo.
- ****: Nâng cấp một release lên phiên bản Chart mới hơn hoặc với một cấu hình khác.bash
# Nâng cấp release 'my-blog' với giá trị mới helm upgrade my-blog bitnami/wordpress --set service.type=LoadBalancer - ****: Quay trở lại một phiên bản trước đó của release. Helm lưu lại lịch sử các lần nâng cấp.bash
helm history my-blog # Xem lịch sử helm rollback my-blog 1 # Quay về phiên bản 1 - ****: Gỡ bỏ một release và xóa tất cả các tài nguyên Kubernetes liên quan.
Chương 14: Xây Dựng Helm Chart của Riêng Bạn
Sử dụng Chart có sẵn rất tuyệt, nhưng sức mạnh thực sự của Helm nằm ở việc bạn có thể đóng gói ứng dụng của chính mình.
14.1. Cấu trúc của một Chart
Helm cung cấp một lệnh để tạo cấu trúc Chart chuẩn:
helm create my-app-chartLệnh này sẽ tạo một thư mục với cấu trúc như sau:
my-app-chart/
├── Chart.yaml # Thông tin metadata về Chart (tên, phiên bản,...)
├── values.yaml # Các giá trị mặc định cho template
├── charts/ # Thư mục chứa các Chart phụ thuộc (sub-charts)
├── templates/ # Thư mục chứa các file template Kubernetes
│ ├── NOTES.txt # Hướng dẫn hiển thị sau khi cài đặt thành công
│ ├── _helpers.tpl # Nơi định nghĩa các template con dùng chung
│ ├── deployment.yaml
│ ├── service.yaml
│ └── ...
└── .helmignore # Các file sẽ bị bỏ qua khi đóng gói Chart14.2. Go Templating Engine: Ngôn ngữ của Helm
Các file trong thư mục không phải là file YAML tĩnh. Chúng là các template được viết bằng ngôn ngữ Go template. Helm sẽ xử lý các template này, điền các giá trị từ vào để tạo ra các file manifest Kubernetes hợp lệ.
14.2.1. Biến, hàm, và pipelines
- Biến: Các giá trị được truy cập qua cú pháp .
- Pipelines: Bạn có thể truyền output của một hàm này làm input cho hàm khác, sử dụng ký tự . Ví dụ: sẽ lấy giá trị, chuyển thành chữ hoa, rồi đặt trong dấu ngoặc kép.
- Hàm: Helm cung cấp rất nhiều hàm hữu ích (xem tài liệu của Sprig).
14.2.2. Các đối tượng tích hợp sẵn
Trong template, bạn có thể truy cập một số đối tượng đặc biệt:
- ****: Đối tượng quan trọng nhất, chứa tất cả các giá trị từ file . Ví dụ: .
- ****: Chứa thông tin về release, như , .
- ****: Chứa thông tin từ file , như , .
Ví dụ trong :
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ .Release.Name }}-{{ .Chart.Name }}
spec:
replicas: {{ .Values.replicaCount }}
template:
spec:
containers:
- name: {{ .Chart.Name }}
image: "{{ .Values.image.repository }}:{{ .Values.image.tag }}"14.2.3. Luồng điều khiển (if/else, range)
- ****: Cho phép bạn tạo ra các khối YAML một cách có điều kiện.yaml
{{- if .Values.ingress.enabled -}} # Khối YAML cho Ingress chỉ được tạo nếu ingress.enabled là true {{- end }} - ****: Lặp qua một danh sách.yaml
ports: {{- range .Values.service.ports }} - port: {{ .port }} targetPort: {{ .targetPort }} protocol: {{ .protocol }} name: {{ .name }} {{- end }}
14.2.4. Named Templates ()
Khi bạn có các khối template phức tạp cần tái sử dụng ở nhiều nơi, bạn có thể định nghĩa chúng trong file .
Ví dụ trong :
{{/* Định nghĩa một template tên là 'my-app-chart.fullname' */}}
{{- define "my-app-chart.fullname" -}}
{{- .Release.Name | trunc 63 | trimSuffix "-" -}}
{{- end -}}Sử dụng trong :
metadata:
name: {{ include "my-app-chart.fullname" . }}14.3. Quản lý các Chart phụ thuộc (Dependencies)
Một ứng dụng có thể cần các ứng dụng khác để hoạt động (ví dụ: web app cần database). Bạn có thể định nghĩa các Chart phụ thuộc trong file .
dependencies:
- name: mariadb
version: "10.5.3"
repository: "https://charts.bitnami.com/bitnami"
condition: mariadb.enabled # Chỉ cài đặt sub-chart này nếu mariadb.enabled là trueChạy để tải các sub-chart về thư mục .
14.4. và : Debugging Chart
- ****: Kiểm tra Chart của bạn xem có tuân thủ các best practice và có lỗi cú pháp không.
- ****: Lệnh cực kỳ hữu ích. Nó sẽ render các template của bạn ra màn hình mà không cần cài đặt vào cluster. Bạn có thể xem chính xác file YAML cuối cùng sẽ trông như thế nào để kiểm tra lỗi.
14.5. Đóng gói và chia sẻ Chart
Khi Chart đã hoàn thiện, bạn có thể đóng gói nó lại:
helm package ./my-app-chart
# Sẽ tạo ra file: my-app-chart-0.1.0.tgzFile này chính là Chart của bạn. Bạn có thể chia sẻ nó cho người khác, hoặc tải nó lên một Chart Repository (như Chartmuseum, Harbor, hoặc GitHub Pages) để chia sẻ rộng rãi.